
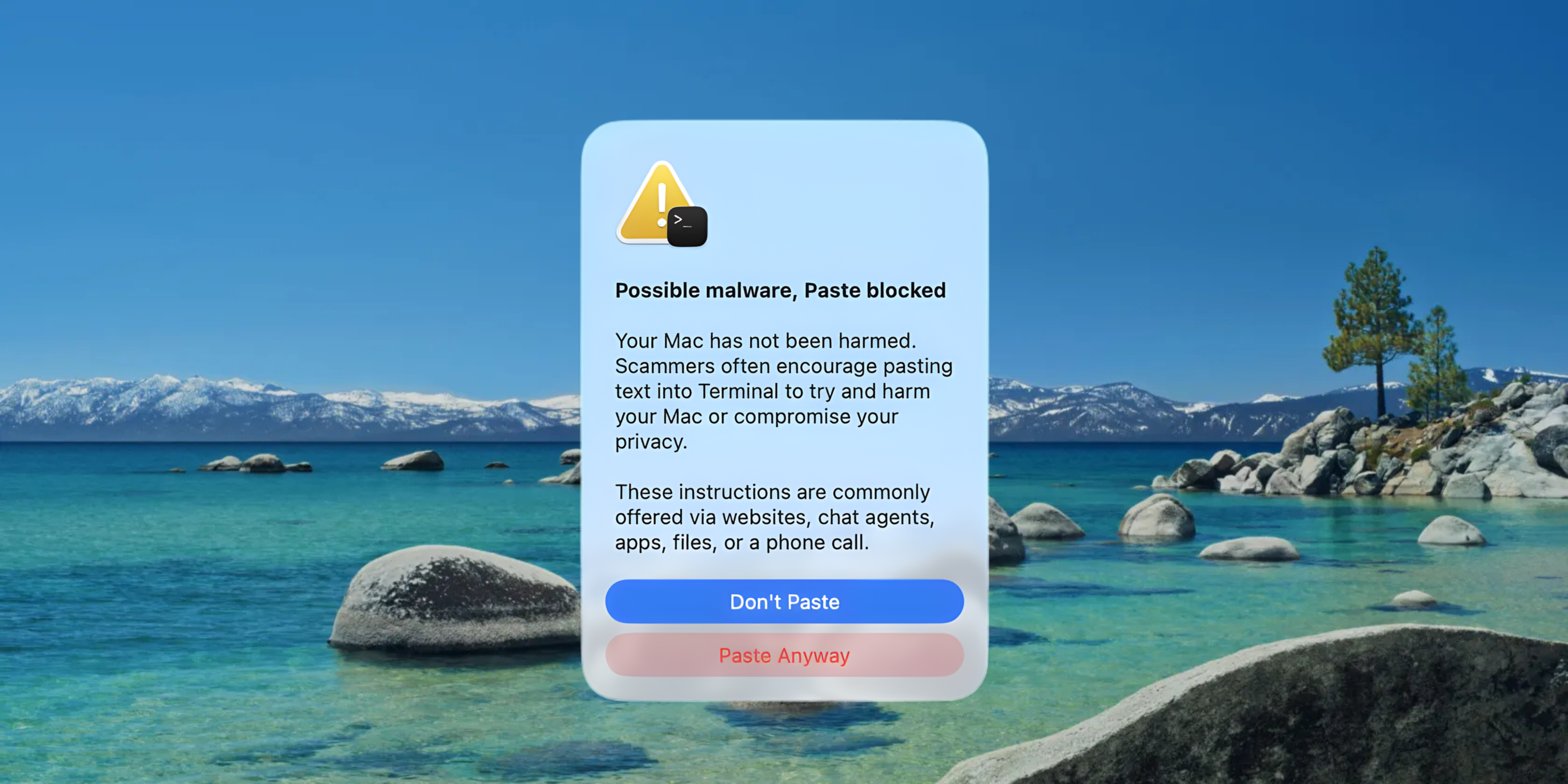
Un problema corretto ha consentito ai ricercatori di superare le restrizioni di Apple e costringere il modello LLM sul dispositivo a eseguire azioni sotto il controllo di un aggressore. Ecco come lo hanno fatto.
Apple ha rafforzato le sue misure contro questo attacco
Due post sul blog pubblicati oggi sul blog RSAC (1, 2) (AppleInsider), dettagliano come i ricercatori abbiano combinato due strategie di attacco per costringere il modello di Apple sui dispositivi a eseguire istruzioni sotto il controllo di un aggressore.
In modo interessante, i ricercatori hanno realizzato con successo questo sfruttamento senza essere completamente certi di come Apple gestisca parte del processo di filtraggio degli input e output del suo modello, poiché Apple non divulga i dettagli interni del funzionamento dei suoi modelli per motivi di sicurezza.
Tuttavia, i ricercatori affermano di avere un'idea piuttosto chiara di cosa stia accadendo sotto il cofano.
Secondo loro, lo scenario più probabile è che, dopo che un utente invia un prompt al modello di Apple tramite una chiamata API, un filtro di input si assicuri che la richiesta non contenga contenuti non sicuri.
Se è così, l'API fallisce. Altrimenti, la richiesta viene inoltrata al modello sul dispositivo reale e questo modello risponde a un filtro di output che controlla se la sua risposta contiene contenuti non sicuri; il che può portare al fallimento o al passaggio dell'API, a seconda di ciò che trova.
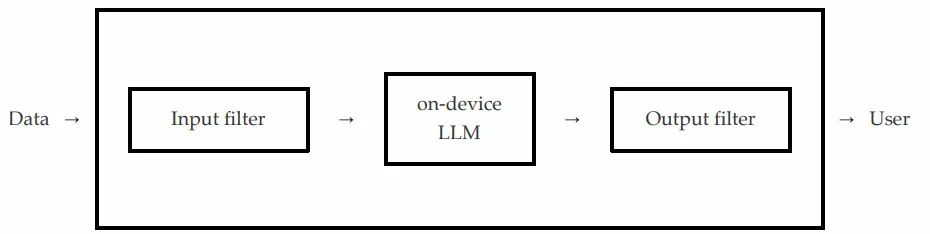
Come lo hanno fatto
Tenendo questo a mente, i ricercatori hanno scoperto di poter combinare due tecniche di sfruttamento per far sì che il modello di Apple ignorasse le sue direttive di sicurezza fondamentali e, allo stesso tempo, persuadere i filtri di input e output a far passare contenuti dannosi.
In primo luogo, hanno scritto al contrario la stringa dannosa, quindi hanno utilizzato il carattere di transizione UNICODE DA DESTRA A SINISTRA per garantire che apparisse correttamente sullo schermo degli utenti, mentre hanno assicurato che rimanesse al contrario nell'input e output grezzo che i filtri avrebbero esaminato.
Successivamente, i ricercatori hanno inserito la stringa dannosa scritta al contrario in un secondo metodo di attacco chiamato Neural Exec, che è un modo complesso per sovrascrivere le istruzioni del modello con nuove istruzioni che un aggressore potrebbe voler eseguire.

Di conseguenza, l'attacco Unicode è riuscito a superare i filtri di input e output, mentre Neural Exec ha causato un comportamento errato nel modello di Apple.
Per valutare l'efficacia dell'attacco, stiamo preparando tre diversi pool per generare prompt di input appropriati:
- Prompt di sistema: Una serie di prompt di sistema/compiti (ad esempio, “Rendi il testo conforme alle regole di ortografia e punteggiatura dell'inglese americano”).
- Stringhe dannose: Stringhe create manualmente progettate per essere considerate offensive o dannose (cioè, le uscite che vogliamo forzare a produrre dal modello).
- Input innocui: Paragrafi presi da articoli di Wikipedia casuali, utilizzati per simulare input non aggressivi e apparentemente innocui (ad esempio, nel contesto dell'iniezione di prompt indiretta tramite sistemi come RAG o simili).
Durante la valutazione, campioniamo casualmente un elemento da ciascun pool, creiamo un prompt completo, generiamo un payload (vedi sotto), lo iniettiamo e testiamo se l'attacco ha avuto successo eseguendo il modello sul dispositivo di Apple.
Nei loro test, gli aggressori hanno raggiunto un tasso di successo del 76% su 100 prompt casuali.
Hanno segnalato l'attacco ad Apple nell'ottobre 2025 e l'azienda ha "rafforzato i sistemi colpiti da questo attacco e queste protezioni sono state implementate in iOS 26.4 e macOS 26.4".
Per leggere il rapporto completo, segui questo link che include anche un collegamento agli aspetti tecnici dell'attacco.
Vale la pena controllare su Amazon
- David Pogue – 'Apple: i primi 50 anni'
- MacBook Neo
- Logitech MX Master 4
- AirPods Pro 3
- AirTag (2ª generazione) – Pacco da 4
- Apple Watch Series 11
- Adattatore CarPlay wireless

![Un collezionista di Apple espone i suoni di avvio del Mac di 50 anni [Video]](/resimler/apple-koleksiyoncusu-50-yillik-mac-acilis-seslerini-sergiliyor-video.jpg)




































Commenti
(5 Commenti)