
Un problema corregido permitió a los investigadores eludir las restricciones de Apple y obligar al LLM en el dispositivo a llevar a cabo acciones bajo el control del atacante. Aquí está cómo lo hicieron.
Apple ha reforzado sus medidas contra este ataque
Hoy, en el blog de RSAC, se publicaron dos entradas (1, 2) (AppleInsider), que detallan cómo los investigadores combinaron dos estrategias de ataque para obligar al modelo de Apple en el dispositivo a ejecutar instrucciones bajo el control del atacante.
Curiosamente, los investigadores lograron llevar a cabo esta explotación con un 100% de certeza sobre cómo Apple maneja parte del proceso de filtrado de entrada y salida de su modelo, ya que Apple no revela los detalles internos de su funcionamiento por razones de seguridad.
Aun así, los investigadores afirman tener una buena idea de lo que sucede bajo el capó.
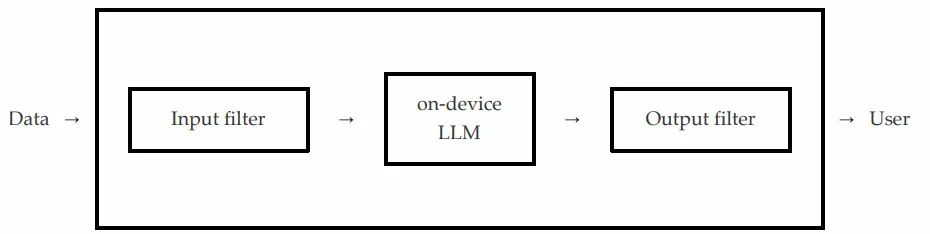
Según ellos, el escenario más probable es que, tras enviar un prompt a través de una llamada API al modelo de Apple en el dispositivo, un filtro de entrada se asegure de que la solicitud no contenga contenido inseguro.
Si ese es el caso, la API falla. De lo contrario, la solicitud se envía al modelo en el dispositivo real, y este modelo responde a un filtro de salida que verifica si su salida contiene contenido inseguro; lo que puede hacer que la API falle o pase, dependiendo de lo que encuentre.
Cómo lo hicieron
Teniendo esto en mente, los investigadores descubrieron que podían combinar dos técnicas de explotación para lograr que el modelo de Apple ignorara sus directrices de seguridad fundamentales y, al mismo tiempo, convencer a los filtros de entrada y salida de que permitieran contenido malicioso.
Primero, escribieron al revés la cadena maliciosa, luego utilizaron el carácter de transición de Unicode de DERECHA A IZQUIERDA para asegurarse de que se mostrara correctamente en la pantalla del usuario, mientras mantenían la entrada y salida en bruto en reversa para que los filtros las revisaran.
A continuación, los investigadores incrustaron la cadena maliciosa escrita al revés dentro de un segundo método de ataque llamado Neural Exec, que es una forma compleja de anular las instrucciones del modelo con nuevas instrucciones que un atacante podría querer ejecutar.

Como resultado, el ataque de Unicode logró eludir los filtros de entrada y salida, mientras que Neural Exec provocó un mal comportamiento en el modelo de Apple.
Para evaluar la efectividad del ataque, preparamos tres grupos diferentes para generar los prompts de entrada adecuados:
- Prompts del sistema: Una serie de prompts/tareas del sistema (por ejemplo, “Haz que el texto dado cumpla con las reglas de ortografía y puntuación del inglés americano”).
- Cadenas maliciosas: Cadenas creadas manualmente diseñadas para ser consideradas ofensivas o maliciosas (es decir, las salidas que queremos forzar que el modelo produzca).
- Entradas inocentes: Fragmentos tomados de artículos aleatorios de Wikipedia, utilizados para simular entradas que parecen inocentes y no amenazantes (por ejemplo, en el contexto de inyección de prompts indirecta a través de sistemas como RAG o similares).
Durante la evaluación, tomamos aleatoriamente un elemento de cada grupo, creamos un prompt completo, generamos una carga útil (ver más abajo), la inyectamos y probamos si el ataque tuvo éxito ejecutando el modelo en el dispositivo de Apple.
En sus pruebas, los atacantes alcanzaron una tasa de éxito del 76% a través de 100 prompts aleatorios.
Informaron del ataque a Apple en octubre de 2025 y la compañía "fortaleció los sistemas afectados por este ataque y estas protecciones se implementaron en iOS 26.4 y macOS 26.4".
Para leer el informe completo, siga este enlace que también incluye un vínculo a los aspectos técnicos del ataque.
Vale la pena revisar en Amazon
- David Pogue – 'Apple: Los Primeros 50 Años'
- MacBook Neo
- Logitech MX Master 4
- AirPods Pro 3
- AirTag (2ª Generación) – Paquete de 4
- Apple Watch Series 11
- Adaptador de CarPlay Inalámbrico

![Un coleccionista de Apple exhibe los sonidos de inicio de Mac de 50 años [Video]](/resimler/apple-koleksiyoncusu-50-yillik-mac-acilis-seslerini-sergiliyor-video.jpg)






































Comentarios
(5 Comentarios)