
Yeni bir çalışmada, bir grup Apple araştırmacısı, matematik akıl yürütme, kod üretimi ve daha fazlasında LLM cevaplarını geliştiren yaratıcı bir çerçeve detaylandırıyor. İşte detaylar.
Difüzyon ve Otoregresyon, Birleşti
Apple araştırmacıları, Kaliforniya Üniversitesi, San Diego'dan araştırmacılarla birlikte, LaDiR: Gizli Difüzyon LLM'leri Metin Akıl Yürütme İçin Geliştirir başlıklı yeni bir çalışmada, büyük dil modellerinin (LLM'ler) belirli alanlarda ürettiği cevapların kalitesini artırmanın ilginç bir yolunu detaylandırıyor.
Geçmişte, her geçişte birçok token üzerinde paralel olarak yineleme yaparak metin üreten difüzyon modellerini, token'ları birer birer hesaplayarak ve tahmin ederek çalışan otoregresif modellerle karşılaştırdık.
Apple, protein katlanma tahmini ve kodlamada uygulanan difüzyon modellerini de inceledi ki bu son derece ilginç.
LaDiR'nin yaptığı şey, kısaca her iki yaklaşımı birleştirmektir: akıl yürütme sürecinde difüzyonu benimser ve ardından nihai çıktıyı otoregresif olarak üretir.
Dahası, aslında birçok akıl yürütme yolunu paralel olarak çalıştırır; her biri kendi difüzyon sürecini yürütür ve farklı olasılıkları keşfetmeleri için bir mekanizma ile desteklenir, böylece çeşitli aday cevaplar üretir.
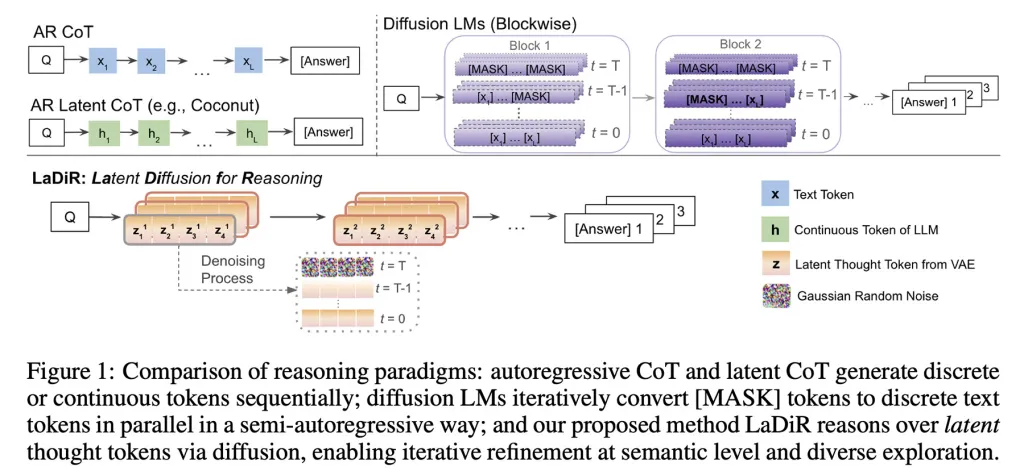
Araştırmacılar, modelin esasen kullanıcıya ne ve nasıl cevap vereceğini düşündüğü çıkarım zamanında, LaDiR'nin her biri rastgele bir desen (veya gürültü) olarak başlayan ve giderek daha tutarlı bir aşamaya rafine edilen bir dizi gizli akıl yürütme bloğu ürettiğini açıklıyor.
Model yeterince akıl yürüttüğünü belirlediğinde, nihai cevabı otoregresif olarak, bir token bir seferde üretecek şekilde geçiş yapar.
Önemli bir detay, LaDiR'nin bu akıl yürütme yollarından birkaçını paralel olarak çalıştırabilmesidir; bu, tüm yolların çok erken aynı fikre yönelmesini önlemek için farklı olasılıkları keşfetmesini teşvik eden bir mekanizma ile desteklenir ve böylece tüm sürecin amacını boşa çıkarmaz.
Önemle belirtmek gerekir ki, LaDiR yeni bir model değil, mevcut dil modellerinin üzerine inşa edilen bir çerçevedir. Tamamen değiştirmek yerine, bir problemi akıl yürütme şekillerini değiştirir.
LaDiR'nin Performansı
Çalışmada, araştırmacılar LaDiR'yi Meta'nın LLaMA 3.1 8B modeline matematik akıl yürütme ve bulmaca planlaması için, Qwen3-8B-Base modeline ise kod üretimi için uyguladılar.
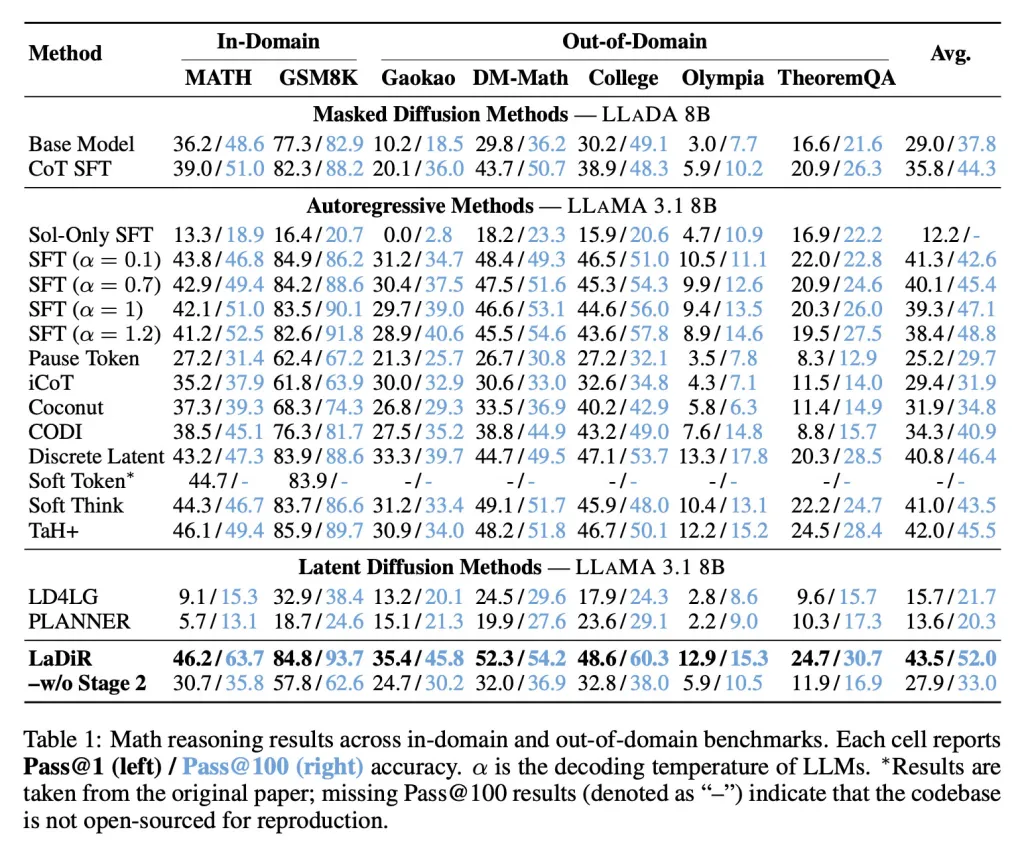
Matematik ölçütlerinde, LaDiR mevcut yaklaşımlardan daha yüksek doğruluk elde etti ve daha zor, dağıtım dışı görevlerde bile daha güçlü bir performans sergiledi.
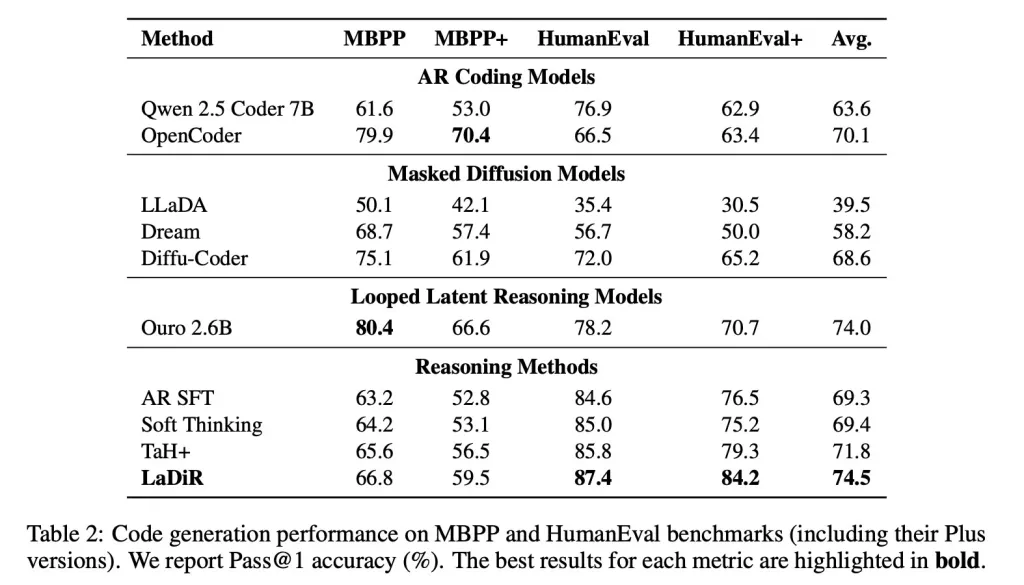
Kod üretimi ölçütlerinde, HumanEval gibi, LaDiR daha güvenilir çıktılar üretti ve standart ince ayarları belirgin bir farkla geride bıraktı, özellikle daha zor problemler üzerinde.
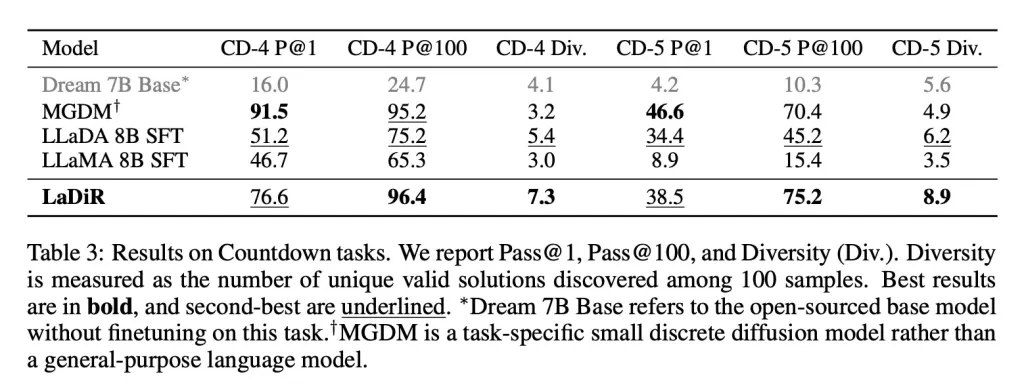
Ve Countdown oyunu gibi bulmaca tarzı planlama görevlerinde, LaDiR, herhangi bir temel modelden daha geniş bir geçerli cevap yelpazesini keşfetti ve tüm genel amaçlı modellerden daha güvenilir bir şekilde doğru çözümler buldu. Ancak, tek deneme doğruluğunda özel, görev odaklı bir modelin gerisinde kaldı.
LaDiR makalesinin bazı yönleri oldukça teknik olabilse de, büyük dil modellerinin iç işleyişine ve metin üretiminde performansı artırmanın yenilikçi yaklaşımlarına ilgi duyuyorsanız, okunmaya değer.
Tam makaleyi okumak için bu bağlantıyı takip edin.


































![Kullanıcı Deneyimi: Bu MagSafe bataryada aradığım bir özellik var [Video]](/resimler/kullanici-deneyimi-bu-magsafe-bataryada-aradigim-bir-ozellik-var-video.jpg)

![Apple koleksiyoncusu 50 yıllık Mac açılış seslerini sergiliyor [Video]](/resimler/apple-koleksiyoncusu-50-yillik-mac-acilis-seslerini-sergiliyor-video.jpg)



Yorumlar
(10 Yorum)