
In un nuovo studio, un gruppo di ricercatori Apple delinea un quadro creativo che migliora le risposte dei LLM nel ragionamento matematico, nella produzione di codice e altro ancora. Ecco i dettagli.
Diffusione e Autoregressione, Unite
I ricercatori Apple, insieme a ricercatori dell'Università della California, San Diego, dettagliano un nuovo studio intitolato LaDiR: Diffusione Nascosta dei LLM per Sviluppare il Ragionamento Testuale, che esplora un modo interessante per migliorare la qualità delle risposte prodotte dai grandi modelli di linguaggio (LLM) in specifici ambiti.
In passato, abbiamo confrontato i modelli di diffusione che generano testo iterando in parallelo su molti token ad ogni passaggio, con modelli autoregressivi che calcolano e prevedono i token uno alla volta.
Apple ha anche esaminato i modelli di diffusione applicati alla previsione del ripiegamento delle proteine e alla codifica, il che è estremamente interessante.
Ciò che LaDiR fa, in breve, è combinare entrambi gli approcci: adotta la diffusione nel processo di ragionamento e poi produce l'output finale in modo autoregressivo.
Inoltre, esegue effettivamente molti percorsi di ragionamento in parallelo; ognuno di essi esegue il proprio processo di diffusione e viene supportato da un meccanismo per esplorare diverse probabilità, producendo così varie risposte candidate.
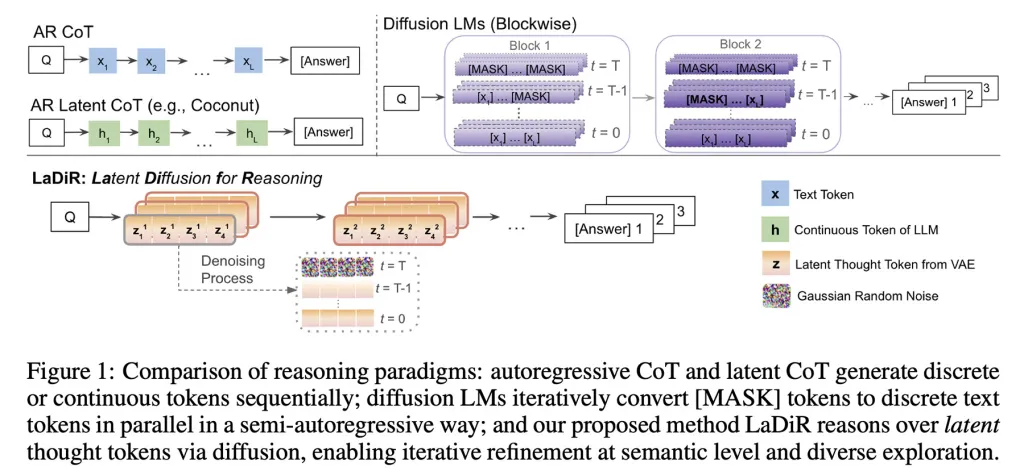
I ricercatori spiegano che, nel momento dell'inferenza, quando il modello determina essenzialmente cosa e come rispondere all'utente, LaDiR produce una serie di blocchi di ragionamento nascosti, ognuno dei quali inizia come un modello casuale (o rumore) e viene progressivamente affinato in una fase più coerente.
Quando il modello determina di aver ragionato a sufficienza, passa a generare l'output finale in modo autoregressivo, producendo un token alla volta.
Un dettaglio importante è che LaDiR può eseguire in parallelo diversi di questi percorsi di ragionamento; questo è supportato da un meccanismo che incoraggia l'esplorazione di diverse probabilità per evitare che tutti i percorsi si dirigano troppo presto verso la stessa idea, mantenendo così l'obiettivo dell'intero processo intatto.
È importante notare che LaDiR non è un nuovo modello, ma un quadro costruito sui modelli di linguaggio esistenti. Invece di sostituire completamente, modifica i modi di ragionare su un problema.
Le Prestazioni di LaDiR
Nello studio, i ricercatori hanno applicato LaDiR al modello LLaMA 3.1 8B di Meta per il ragionamento matematico e la pianificazione dei puzzle, mentre per la produzione di codice hanno utilizzato il modello Qwen3-8B-Base.
Nei criteri matematici, LaDiR ha ottenuto una maggiore accuratezza rispetto agli approcci esistenti e ha mostrato prestazioni più forti anche in compiti più difficili e fuori distribuzione.
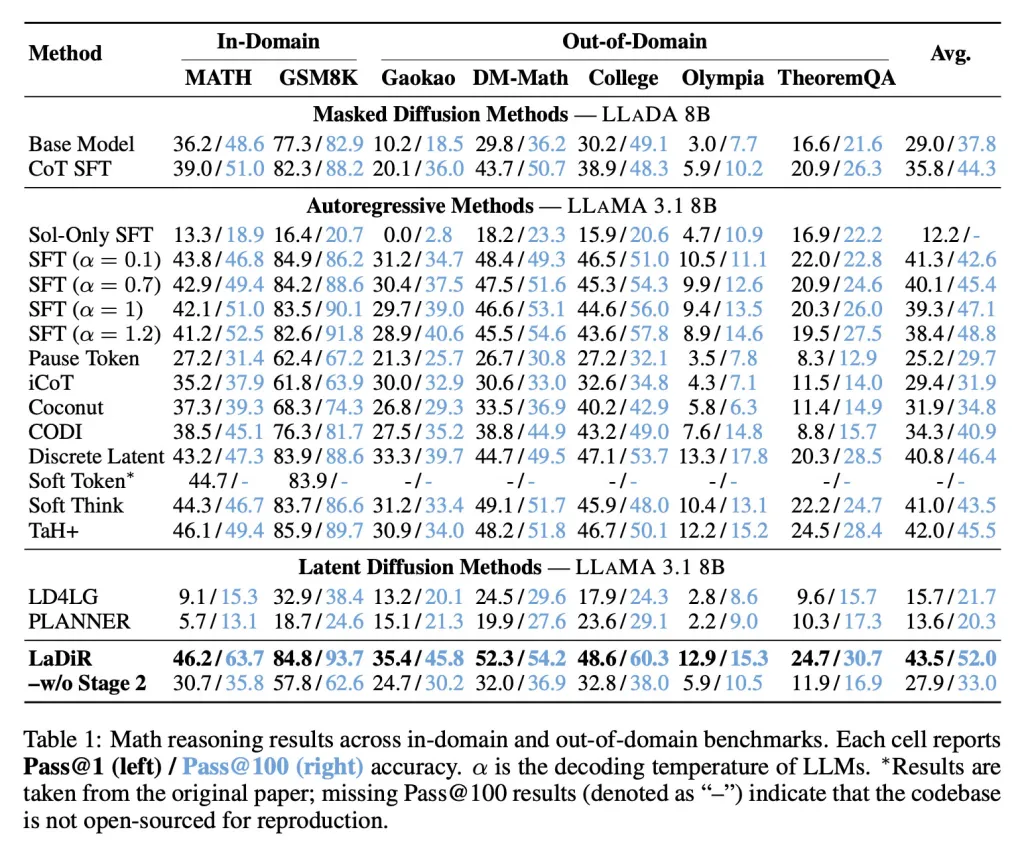
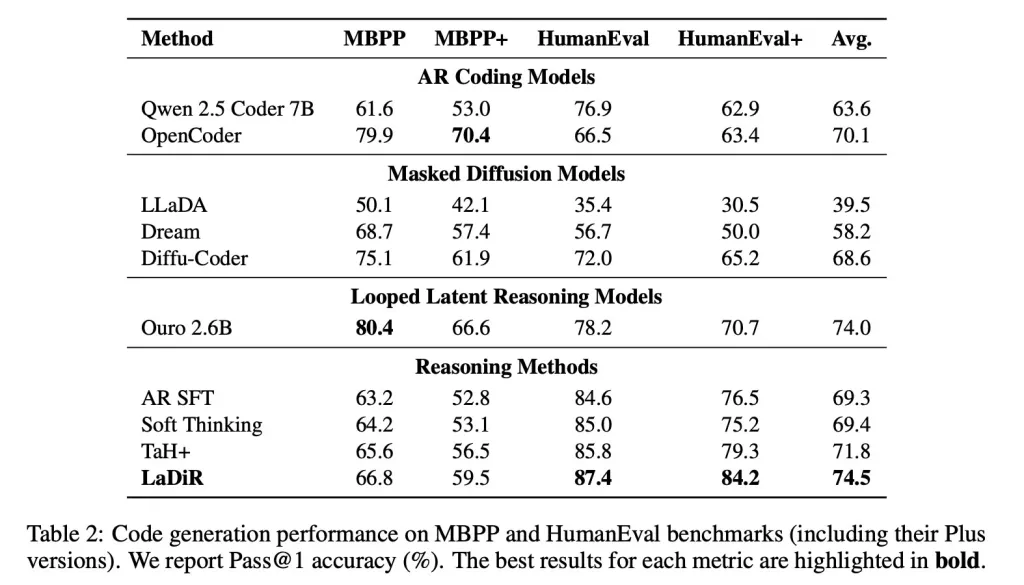
Nei criteri di produzione di codice, come HumanEval, LaDiR ha prodotto output più affidabili e ha superato le regolazioni standard con una differenza significativa, specialmente su problemi più difficili.
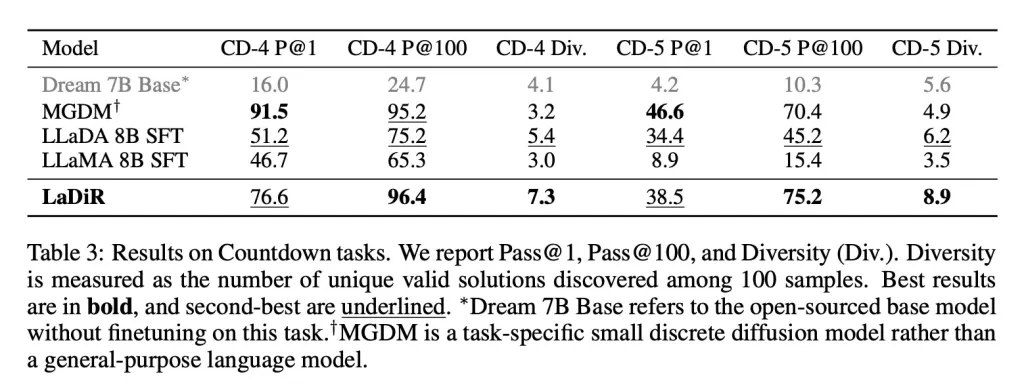
In compiti di pianificazione di tipo puzzle come il gioco Countdown, LaDiR ha esplorato un'ampia gamma di risposte valide rispetto a qualsiasi modello di base e ha trovato soluzioni corrette in modo più affidabile rispetto a tutti i modelli generali. Tuttavia, è rimasto indietro rispetto a un modello specifico e focalizzato sul compito in termini di accuratezza in un singolo tentativo.
Alcuni aspetti dell'articolo su LaDiR possono essere piuttosto tecnici, ma se sei interessato al funzionamento interno dei grandi modelli di linguaggio e a approcci innovativi per migliorare le prestazioni nella produzione di testo, vale la pena leggerlo.
Segui questo link per leggere l'articolo completo.






































Commenti
(10 Commenti)