
In a new study, a group of Apple researchers details a creative framework that enhances LLM responses in mathematical reasoning, code generation, and more. Here are the details.
Diffusion and Autoregression Combined
Apple researchers, in collaboration with researchers from the University of California, San Diego, detail an interesting way to improve the quality of responses produced by large language models (LLMs) in a new study titled LaDiR: Developing Latent Diffusion LLMs for Text Reasoning.
In the past, we compared diffusion models that generate text by iterating over many tokens in parallel at each step with autoregressive models that compute and predict tokens one by one.
Apple also examined diffusion models applied to protein folding prediction and coding, which is extremely interesting.
What LaDiR does is, in short, combine both approaches: it adopts diffusion in the reasoning process and then generates the final output autoregressively.
Moreover, it actually runs many reasoning paths in parallel; each conducts its own diffusion process and is supported by a mechanism to explore different probabilities, thus producing various candidate responses.
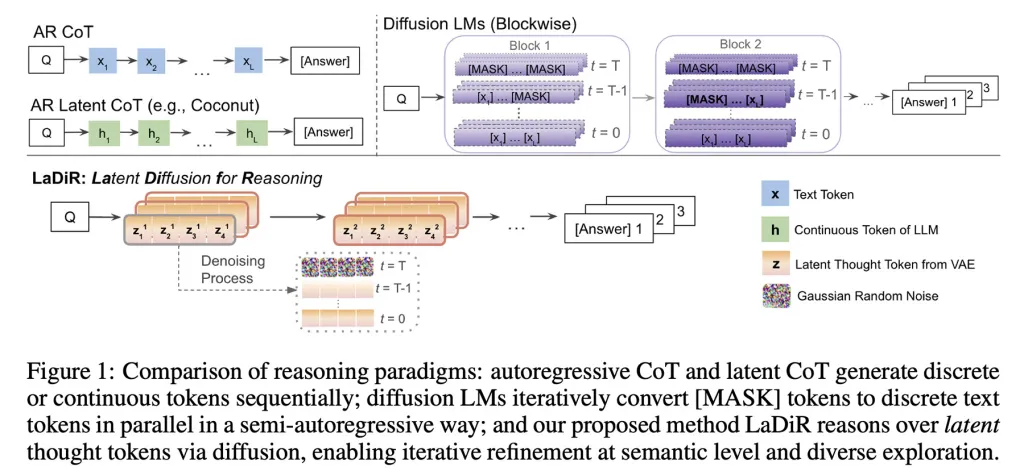
The researchers explain that at inference time, when the model essentially considers what and how to respond to the user, LaDiR produces a series of latent reasoning blocks, each starting as a random pattern (or noise) and gradually refined to a more coherent stage.
When the model determines that it has reasoned sufficiently, it transitions to generate the final answer autoregressively, one token at a time.
Importantly, LaDiR can run several of these reasoning paths in parallel; this is supported by a mechanism that encourages exploration of different probabilities to prevent all paths from converging on the same idea too early, thus not undermining the purpose of the entire process.
It is important to note that LaDiR is not a new model but a framework built on existing language models. Instead of completely changing them, it alters how a problem is reasoned.
Performance of LaDiR
In the study, the researchers applied LaDiR to Meta's LLaMA 3.1 8B model for mathematical reasoning and puzzle planning, and to the Qwen3-8B-Base model for code generation.
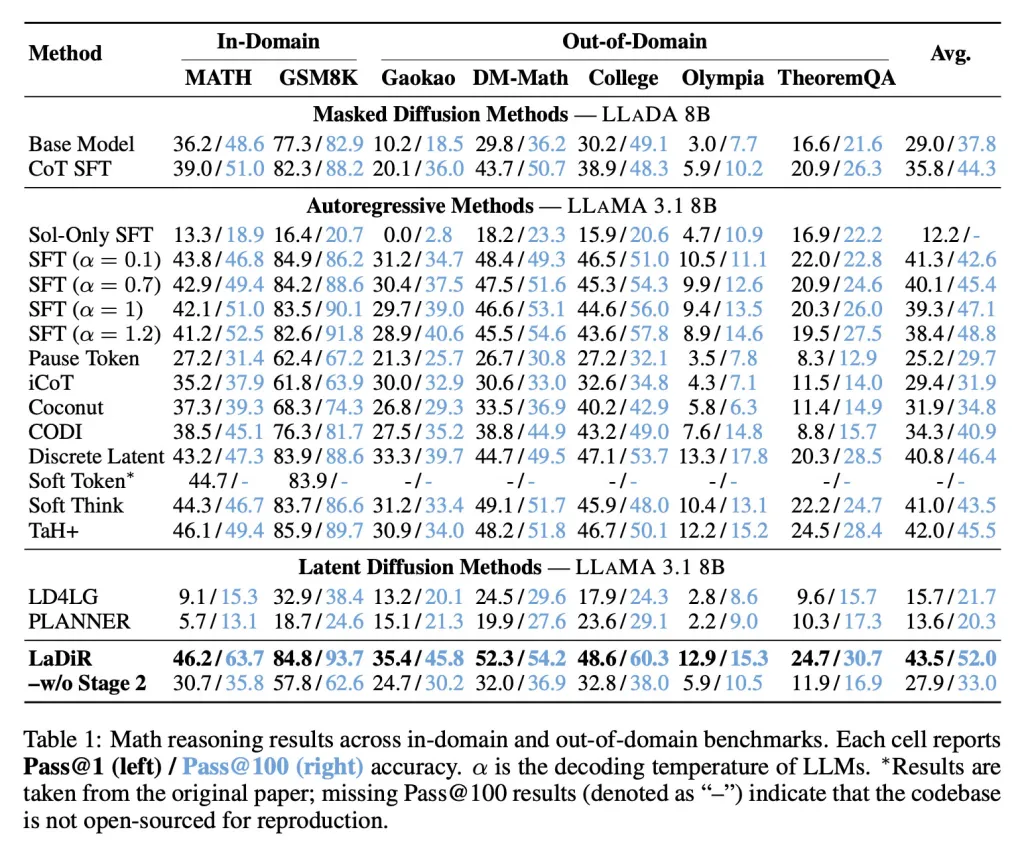
In mathematical metrics, LaDiR achieved higher accuracy than existing approaches and demonstrated stronger performance even on more difficult, out-of-distribution tasks.
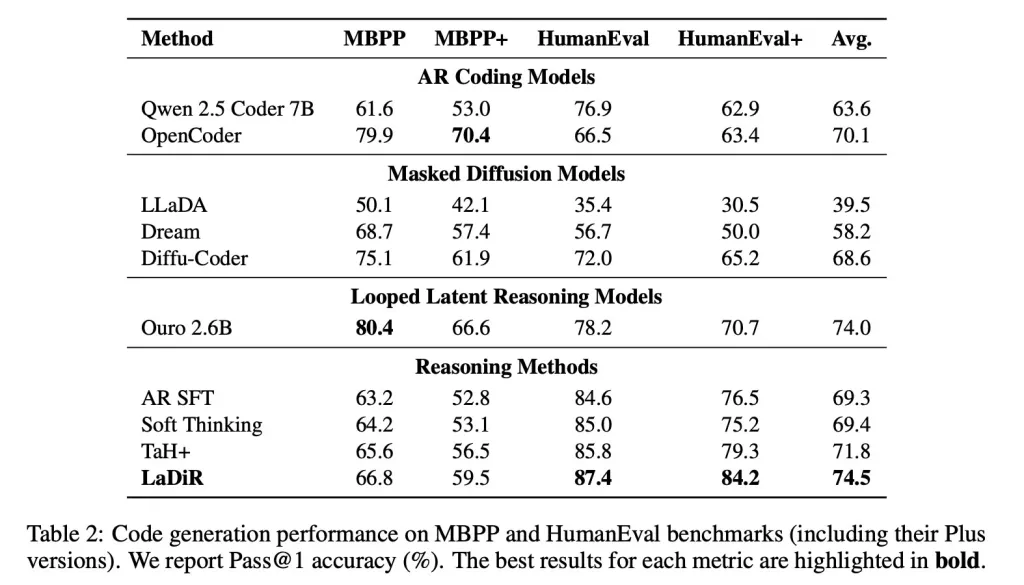
In code generation metrics, like HumanEval, LaDiR produced more reliable outputs and significantly outperformed standard fine-tunings, particularly on harder problems.
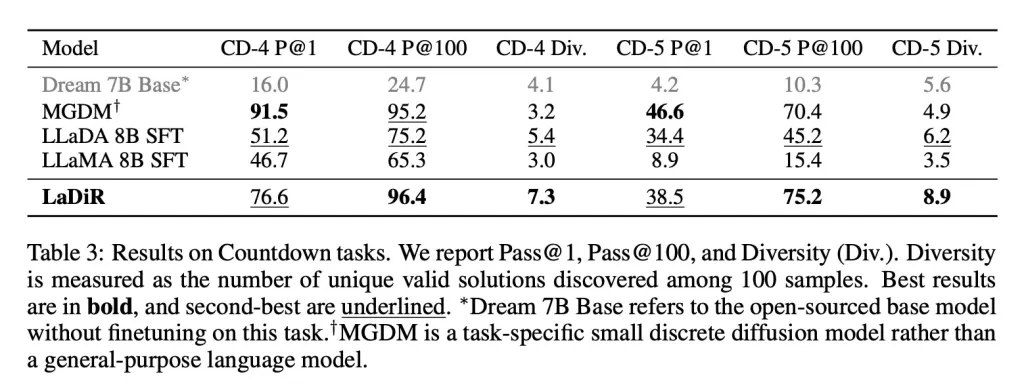
And in puzzle-style planning tasks like the Countdown game, LaDiR explored a broader range of valid answers than any base model and found correct solutions more reliably than all general-purpose models. However, it fell short of a specialized, task-focused model in single-attempt accuracy.
While some aspects of the LaDiR paper can be quite technical, it is worth reading if you are interested in the inner workings of large language models and innovative approaches to enhancing performance in text generation.
Follow this link to read the full article.

![iPhone 17e: Apple Finally Got the Affordable iPhone Right [Video]](/resimler/iphone-17e-apple-nihayet-uygun-fiyatli-iphoneu-dogru-yapti-video.jpg)




















![The Best (and Worst) Apple Products of the Tim Cook Era [Video]](/resimler/tim-cook-donemindeki-en-iyi-ve-en-kotu-apple-urunleri-video.jpg)




















Comments
(10 Comments)