
Em um novo estudo, um grupo de pesquisadores da Apple detalha uma estrutura criativa que melhora as respostas de LLM em raciocínio matemático, geração de código e muito mais. Aqui estão os detalhes.
Difusão e Autoregressão, Combinadas
Pesquisadores da Apple, em colaboração com pesquisadores da Universidade da Califórnia, San Diego, detalham uma maneira interessante de aumentar a qualidade das respostas produzidas por grandes modelos de linguagem (LLMs) em áreas específicas em um novo estudo intitulado LaDiR: Difusão Secreta de LLMs para Raciocínio Textual.
No passado, comparamos modelos de difusão que geram texto iterando paralelamente sobre muitos tokens em cada passagem com modelos autoregressivos que funcionam calculando e prevendo tokens um a um.
A Apple também investigou modelos de difusão aplicados à previsão de dobramento de proteínas e codificação, o que é extremamente interessante.
O que o LaDiR faz, em resumo, é combinar ambas as abordagens: adota a difusão no processo de raciocínio e, em seguida, produz a saída final de forma autoregressiva.
Além disso, na verdade, executa muitos caminhos de raciocínio em paralelo; cada um conduz seu próprio processo de difusão e é apoiado por um mecanismo que os ajuda a explorar diferentes probabilidades, gerando assim várias respostas candidatas.
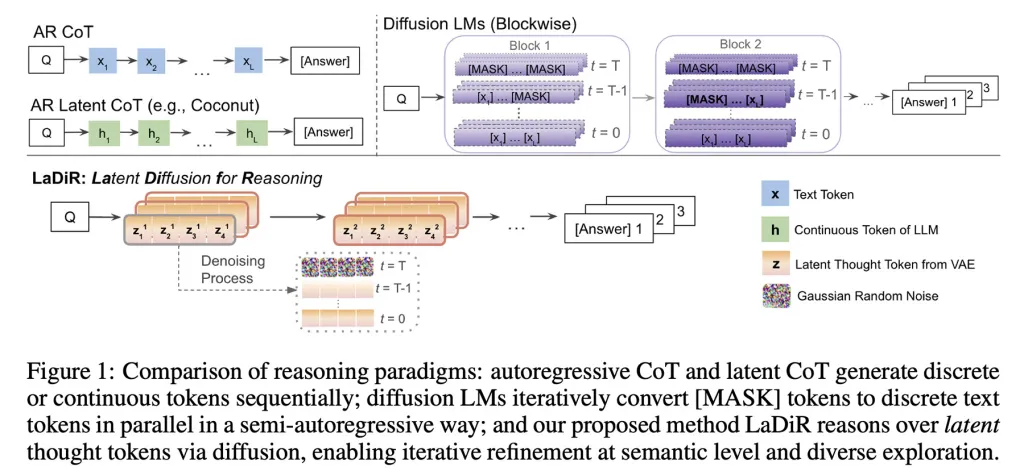
Os pesquisadores explicam que, no momento da inferência, quando o modelo essencialmente considera o que e como responder ao usuário, o LaDiR produz uma série de blocos de raciocínio ocultos que começam como um padrão (ou ruído) aleatório e são refinados para uma fase cada vez mais consistente.
Quando o modelo determina que raciocinou o suficiente, ele muda para produzir a resposta final de forma autoregressiva, gerando um token de cada vez.
Um detalhe importante é que o LaDiR pode executar vários desses caminhos de raciocínio em paralelo; isso é apoiado por um mecanismo que incentiva a exploração de diferentes probabilidades para evitar que todos os caminhos se direcionem muito cedo para a mesma ideia, assim não comprometendo o objetivo de todo o processo.
É importante ressaltar que o LaDiR não é um novo modelo, mas uma estrutura construída sobre modelos de linguagem existentes. Em vez de mudar completamente, altera a forma como um problema é raciocinado.
Desempenho do LaDiR
No estudo, os pesquisadores aplicaram o LaDiR ao modelo LLaMA 3.1 8B da Meta para raciocínio matemático e planejamento de quebra-cabeças, e ao modelo Qwen3-8B-Base para geração de código.
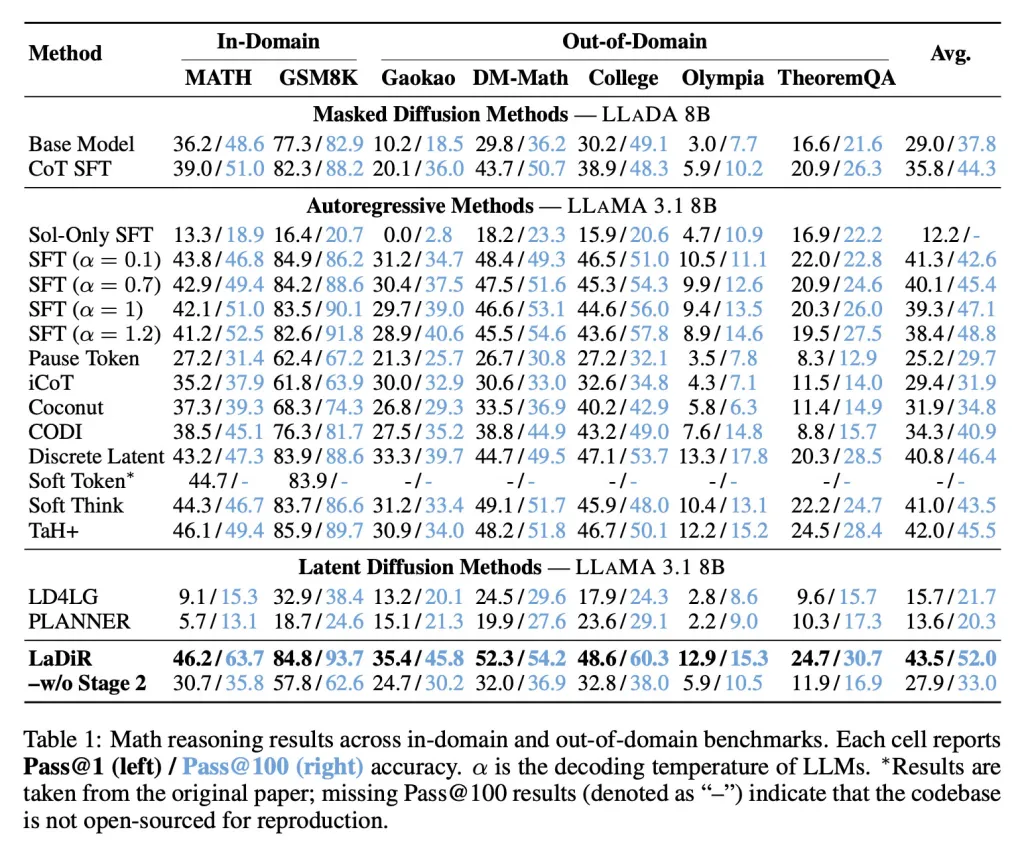
Nos critérios matemáticos, o LaDiR obteve uma precisão mais alta do que as abordagens existentes e mostrou um desempenho ainda mais forte em tarefas mais difíceis e fora da distribuição.
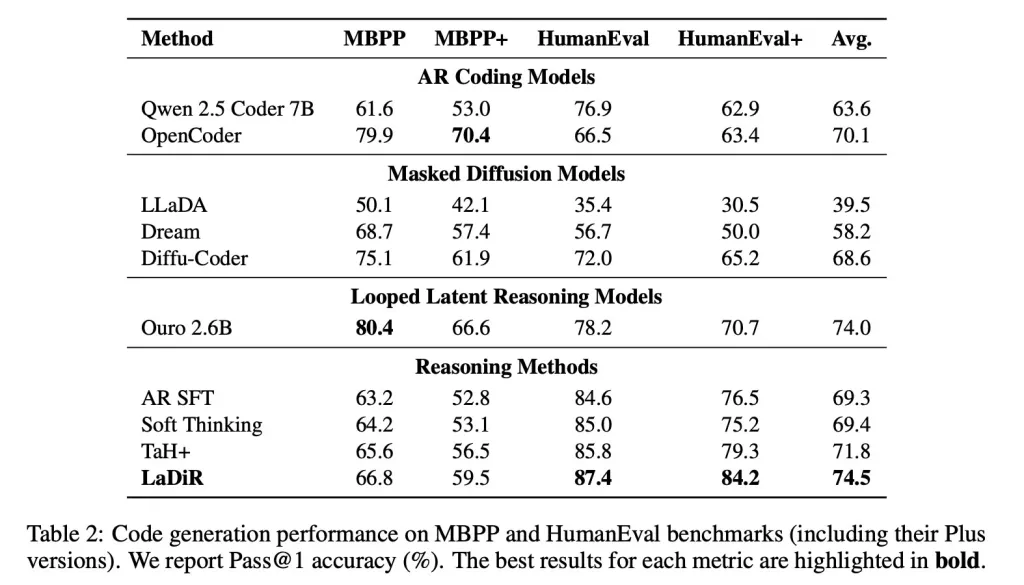
Nos critérios de geração de código, como o HumanEval, o LaDiR produziu saídas mais confiáveis e superou os ajustes padrão com uma diferença notável, especialmente em problemas mais difíceis.
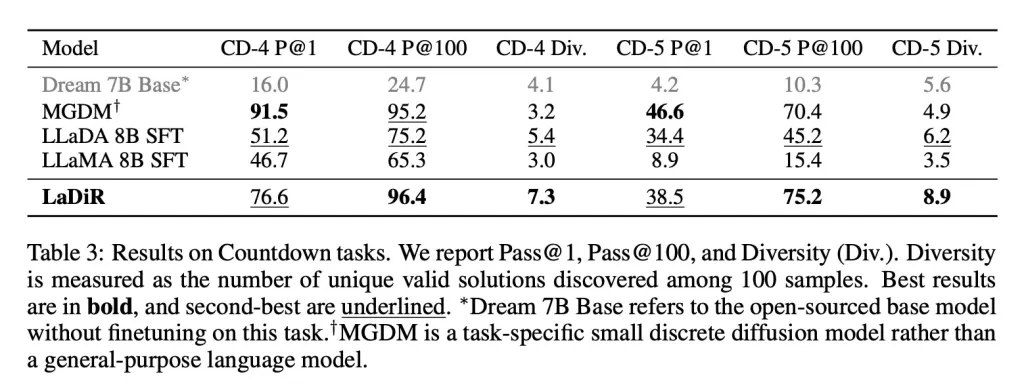
E em tarefas de planejamento de quebra-cabeças, como o jogo Countdown, o LaDiR explorou uma gama mais ampla de respostas válidas do que qualquer modelo base e encontrou soluções corretas de forma mais confiável do que todos os modelos de propósito geral. No entanto, ficou atrás de um modelo específico e focado em tarefas em termos de precisão em uma única tentativa.
Embora alguns aspectos do artigo do LaDiR possam ser bastante técnicos, vale a pena ler se você estiver interessado na mecânica interna dos grandes modelos de linguagem e em abordagens inovadoras para melhorar o desempenho na geração de texto.
Siga este link para ler o artigo completo.

















![Experiência do Usuário: Há um recurso que eu procurava nesta bateria MagSafe [Vídeo]](/resimler/kullanici-deneyimi-bu-magsafe-bataryada-aradigim-bir-ozellik-var-video.jpg)




















Comentários
(10 Comentários)