
In einer neuen Studie erläutert eine Gruppe von Apple-Forschern einen kreativen Rahmen, der die Antworten von LLM in mathematischer Argumentation, Code-Generierung und mehr verbessert. Hier sind die Details.
Diffusion und Autoregression vereint
Die Apple-Forscher beschreiben zusammen mit Forschern der University of California, San Diego in einer neuen Studie mit dem Titel LaDiR: Geheime Diffusions-LLMs zur Textargumentation entwickeln einen interessanten Weg zur Verbesserung der Qualität der von großen Sprachmodellen (LLMs) in bestimmten Bereichen erzeugten Antworten.
In der Vergangenheit haben wir Diffusionsmodelle, die Text erzeugen, indem sie in jeder Iteration parallel über viele Tokens iterieren, mit autoregressiven Modellen verglichen, die Tokens einzeln berechnen und vorhersagen.
Apple hat auch Diffusionsmodelle untersucht, die auf die Vorhersage der Proteinstruktur und die Kodierung angewendet werden, was äußerst interessant ist.
Was LaDiR tut, ist kurz gesagt, beide Ansätze zu kombinieren: Es übernimmt die Diffusion im Argumentationsprozess und erzeugt dann die endgültige Ausgabe autoregressiv.
Darüber hinaus führt es tatsächlich viele Argumentationswege parallel aus; jeder führt seinen eigenen Diffusionsprozess durch und wird durch einen Mechanismus unterstützt, der es ihnen ermöglicht, verschiedene Wahrscheinlichkeiten zu erkunden, wodurch verschiedene Kandidatenantworten erzeugt werden.
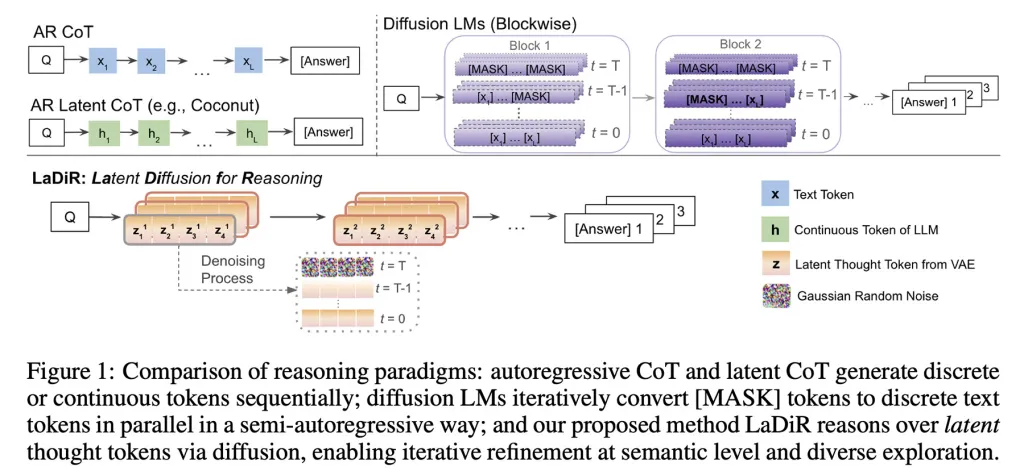
Die Forscher erklären, dass das Modell im Wesentlichen zur Inferenzzeit darüber nachdenkt, was und wie es dem Benutzer antworten soll, und dass LaDiR eine Reihe von geheimen Argumentationsblöcken erzeugt, die jeweils als zufälliges Muster (oder Rauschen) beginnen und schrittweise zu einer konsistenteren Phase verfeinert werden.
Wenn das Modell feststellt, dass es ausreichend argumentiert hat, wechselt es zur autoregressiven Erzeugung der endgültigen Antwort, indem es ein Token nach dem anderen produziert.
Ein wichtiger Punkt ist, dass LaDiR in der Lage ist, mehrere dieser Argumentationswege parallel auszuführen; dies wird durch einen Mechanismus unterstützt, der es fördert, verschiedene Wahrscheinlichkeiten zu erkunden, um zu verhindern, dass alle Wege zu früh auf dieselbe Idee zusteuern, und so den Zweck des gesamten Prozesses nicht untergräbt.
Es ist wichtig zu betonen, dass LaDiR kein neues Modell ist, sondern ein Rahmen, der auf bestehenden Sprachmodellen aufbaut. Anstatt vollständig zu verändern, verändert es die Art und Weise, wie ein Problem argumentiert wird.
Die Leistung von LaDiR
In der Studie wendeten die Forscher LaDiR auf Meta's LLaMA 3.1 8B-Modell für mathematische Argumentation und Rätselplanung an, und auf das Qwen3-8B-Base-Modell für die Code-Generierung.
In mathematischen Maßstäben erzielte LaDiR eine höhere Genauigkeit als bestehende Ansätze und zeigte sogar bei schwierigeren, verteilungsfremden Aufgaben eine stärkere Leistung.
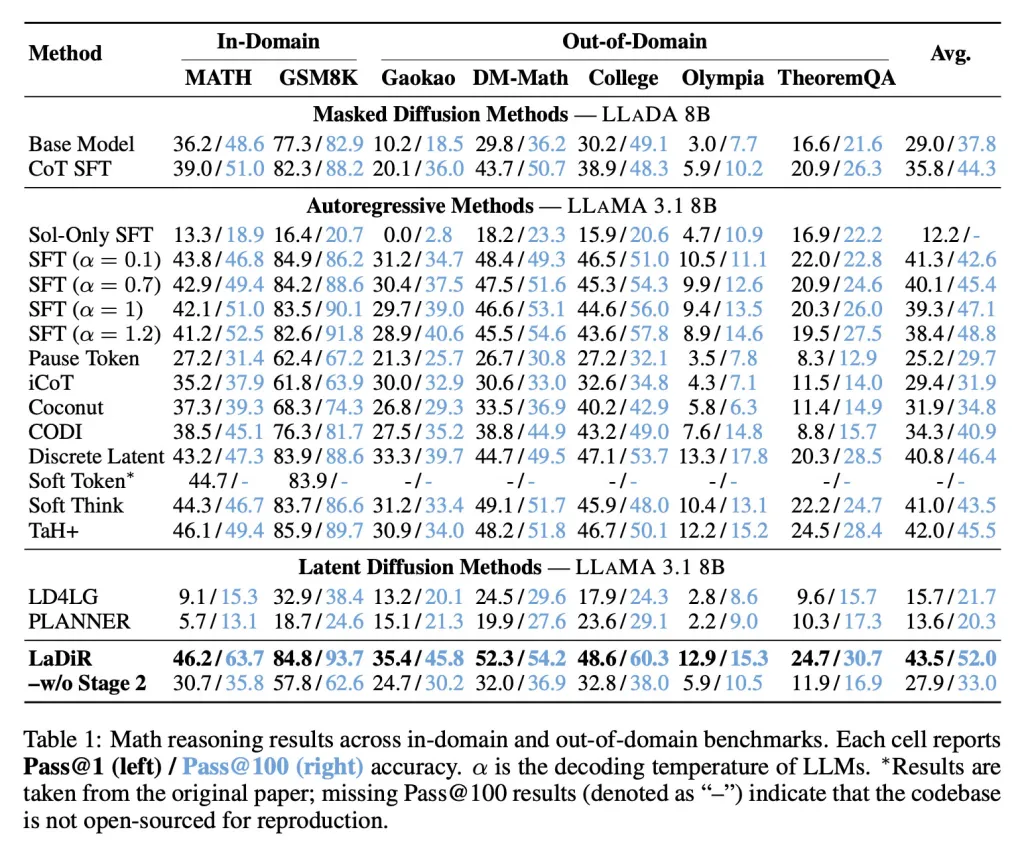
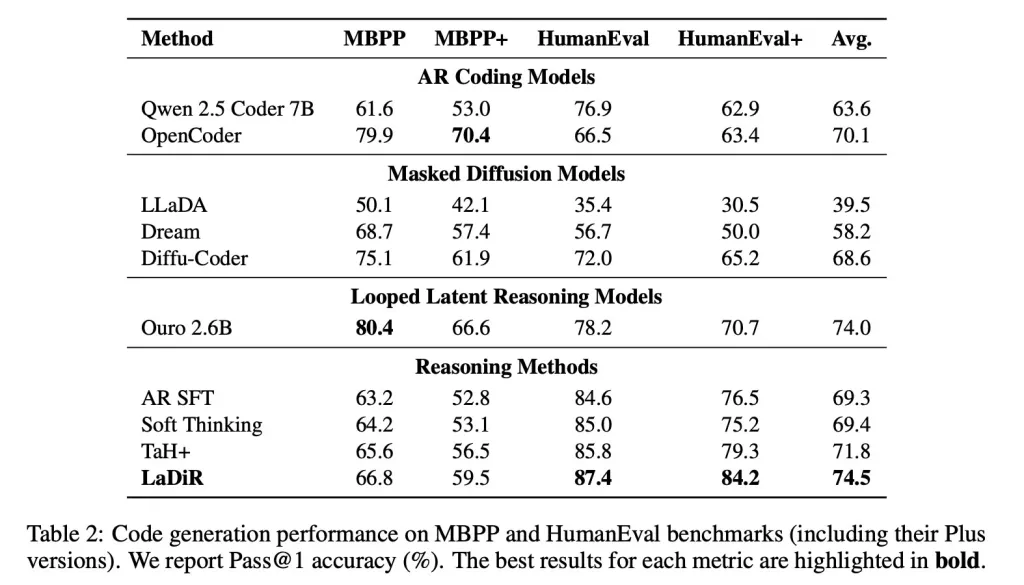
In den Maßstäben der Code-Generierung, wie HumanEval, erzeugte LaDiR zuverlässigere Ausgaben und übertraf die Standardanpassungen mit einem deutlichen Unterschied, insbesondere bei schwierigeren Problemen.
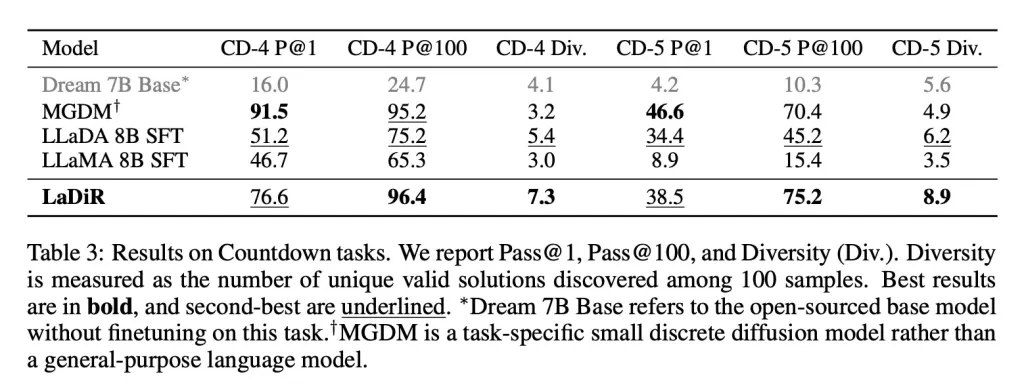
Und bei puzzleartigen Planungsaufgaben wie dem Countdown-Spiel entdeckte LaDiR ein breiteres Spektrum an gültigen Antworten als jedes Basis-Modell und fand zuverlässiger als alle allgemeinen Modelle korrekte Lösungen. Allerdings blieb es in der Genauigkeit bei einzelnen Versuchen hinter einem spezialisierten, aufgabenorientierten Modell zurück.
Einige Aspekte des LaDiR-Artikels können zwar recht technisch sein, aber wenn Sie an den inneren Abläufen großer Sprachmodelle und innovativen Ansätzen zur Verbesserung der Leistung in der Texterzeugung interessiert sind, ist es lesenswert.
Folgen Sie diesem Link, um den vollständigen Artikel zu lesen.








































Kommentare
(10 Kommentare)