
Dans une nouvelle étude, un groupe de chercheurs d'Apple détaille un cadre créatif qui améliore les réponses des LLM en raisonnement mathématique, en génération de code et plus encore. Voici les détails.
Diffusion et Autorégression, Fusionnées
Les chercheurs d'Apple, en collaboration avec des chercheurs de l'Université de Californie à San Diego, détaillent dans une nouvelle étude intitulée LaDiR : Développement de LLM de Diffusion Cachée pour le Raisonnement Textuel, une méthode intéressante pour améliorer la qualité des réponses produites par les grands modèles de langage (LLM) dans des domaines spécifiques.
Dans le passé, nous avons comparé les modèles de diffusion qui génèrent du texte en itérant parallèlement sur de nombreux tokens à chaque étape, avec des modèles autorégressifs qui calculent et prédisent les tokens un par un.
Apple a également examiné les modèles de diffusion appliqués à la prédiction du repliement des protéines et à la codification, ce qui est extrêmement intéressant.
Ce que fait LaDiR, en résumé, c'est combiner les deux approches : il adopte la diffusion dans le processus de raisonnement et produit ensuite la sortie finale de manière autorégressive.
De plus, il exécute en réalité plusieurs chemins de raisonnement en parallèle ; chacun d'eux mène son propre processus de diffusion et est soutenu par un mécanisme qui leur permet d'explorer différentes probabilités, produisant ainsi diverses réponses candidates.
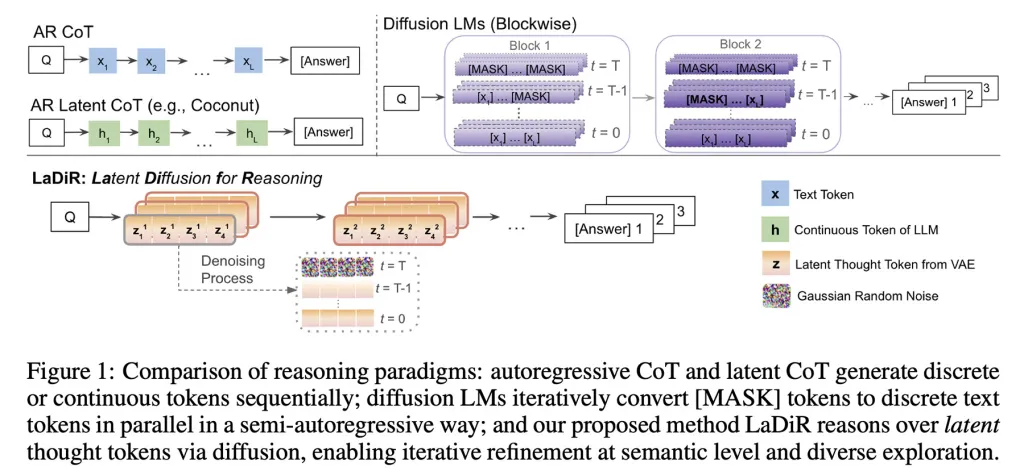
Les chercheurs expliquent qu'au moment de l'inférence, lorsque le modèle détermine essentiellement ce qu'il doit répondre et comment, LaDiR produit une série de blocs de raisonnement cachés, chacun commençant par un motif (ou bruit) aléatoire et raffinant progressivement vers une étape plus cohérente.
Lorsque le modèle détermine qu'il a suffisamment raisonné, il passe à la génération de la réponse finale de manière autorégressive, produisant un token à la fois.
Un détail important est que LaDiR peut exécuter plusieurs de ces chemins de raisonnement en parallèle ; cela est soutenu par un mécanisme qui encourage l'exploration de différentes probabilités pour éviter que tous les chemins ne convergent trop tôt vers la même idée, préservant ainsi l'objectif de l'ensemble du processus.
Il convient de noter que LaDiR n'est pas un nouveau modèle, mais un cadre construit sur des modèles de langage existants. Au lieu de changer complètement, il modifie la manière dont un problème est raisonné.
Performance de LaDiR
Dans l'étude, les chercheurs ont appliqué LaDiR au modèle LLaMA 3.1 8B de Meta pour le raisonnement mathématique et la planification de puzzles, et au modèle Qwen3-8B-Base pour la génération de code.
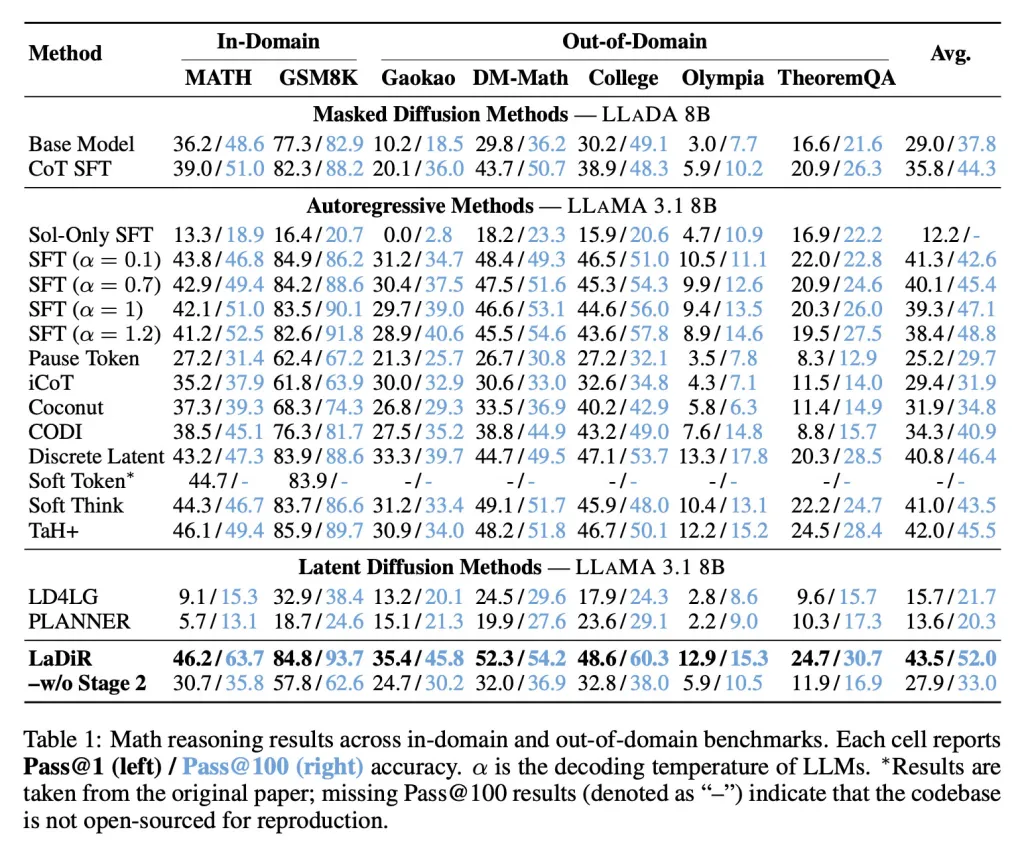
En termes de critères mathématiques, LaDiR a obtenu une précision plus élevée que les approches existantes et a montré une performance plus forte même sur des tâches plus difficiles et hors distribution.
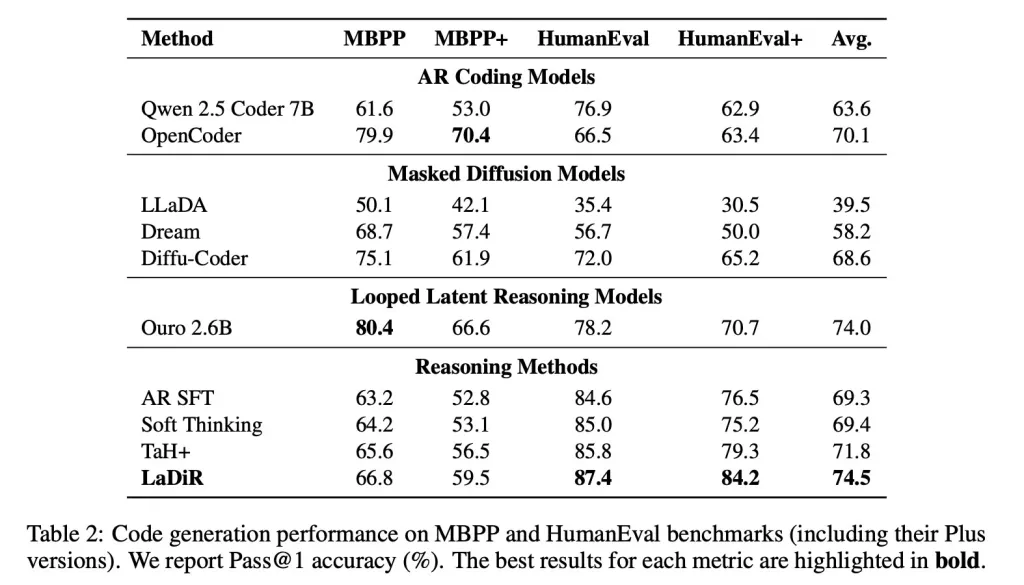
En termes de critères de génération de code, comme HumanEval, LaDiR a produit des sorties plus fiables et a largement surpassé les réglages standards, en particulier sur des problèmes plus difficiles.
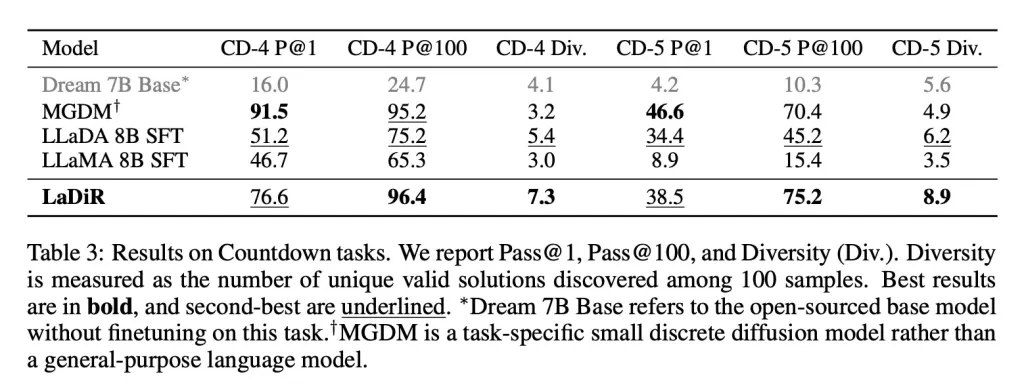
Et dans des tâches de planification de type puzzle comme le jeu Countdown, LaDiR a exploré une gamme de réponses valides plus large que n'importe quel modèle de base et a trouvé des solutions correctes de manière plus fiable que tous les modèles à usage général. Cependant, il a été dépassé en précision à un seul essai par un modèle spécifique axé sur la tâche.
Bien que certains aspects de l'article sur LaDiR puissent être assez techniques, il vaut la peine d'être lu si vous êtes intéressé par le fonctionnement interne des grands modèles de langage et par des approches innovantes pour améliorer la performance en génération de texte.
Pour lire l'article complet, suivez ce lien.



















![Les Meilleurs (et Pires) Produits Apple Sous Tim Cook [Vidéo]](/resimler/tim-cook-donemindeki-en-iyi-ve-en-kotu-apple-urunleri-video.jpg)























Commentaires
(10 Commentaires)