
En un nuevo estudio, un grupo de investigadores de Apple detalla un marco creativo que mejora las respuestas de los LLM en razonamiento matemático, generación de código y más. Aquí están los detalles.
Difusión y Autoregresión, Combinados
Los investigadores de Apple, junto con investigadores de la Universidad de California, San Diego, detallan un nuevo estudio titulado LaDiR: Difusión Oculta de LLMs para el Razonamiento Textual, que describe una forma interesante de mejorar la calidad de las respuestas producidas por los grandes modelos de lenguaje (LLMs) en áreas específicas.
En el pasado, comparamos los modelos de difusión que generan texto iterando en paralelo sobre muchos tokens en cada paso, con modelos autoregresivos que calculan y predicen los tokens uno por uno.
Apple también examinó modelos de difusión aplicados a la predicción del plegamiento de proteínas y la codificación, lo cual es extremadamente interesante.
Lo que hace LaDiR, en resumen, es combinar ambos enfoques: adopta la difusión en el proceso de razonamiento y luego produce la salida final de manera autoregresiva.
Además, en realidad ejecuta muchos caminos de razonamiento en paralelo; cada uno lleva a cabo su propio proceso de difusión y está respaldado por un mecanismo que les permite explorar diferentes probabilidades, generando así diversas respuestas candidatas.
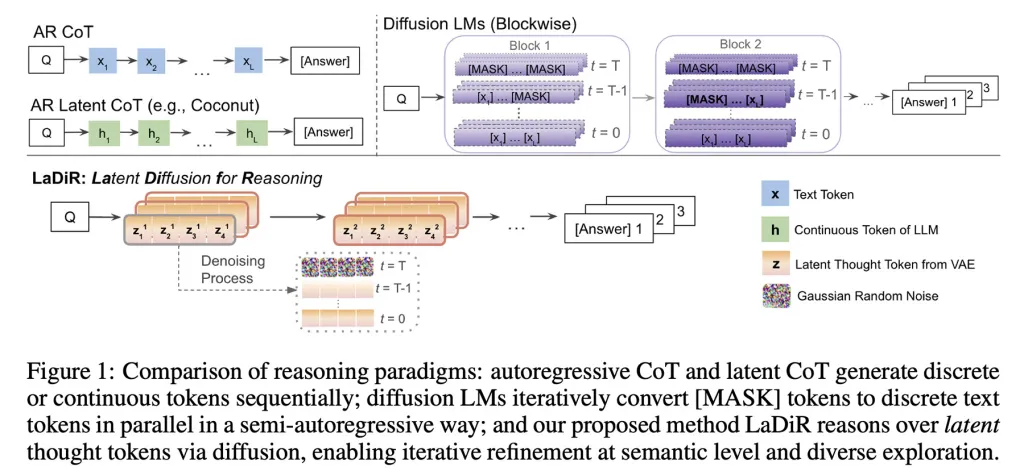
Los investigadores explican que, en el momento de la inferencia, cuando el modelo determina esencialmente qué y cómo responder al usuario, LaDiR produce una serie de bloques de razonamiento oculto que comienzan como un patrón (o ruido) aleatorio y se refinan a una etapa cada vez más coherente.
Cuando el modelo determina que ha razonado lo suficiente, pasa a generar la respuesta final de manera autoregresiva, produciendo un token a la vez.
Un detalle importante es que LaDiR puede ejecutar varios de estos caminos de razonamiento en paralelo; esto está respaldado por un mecanismo que fomenta la exploración de diferentes probabilidades para evitar que todos los caminos se dirijan demasiado pronto hacia la misma idea, de modo que no se comprometa el propósito de todo el proceso.
Es importante señalar que LaDiR no es un nuevo modelo, sino un marco construido sobre modelos de lenguaje existentes. En lugar de cambiar completamente, modifica la forma en que se razona un problema.
El Rendimiento de LaDiR
En el estudio, los investigadores aplicaron LaDiR al modelo LLaMA 3.1 8B de Meta para razonamiento matemático y planificación de rompecabezas, y al modelo Qwen3-8B-Base para generación de código.
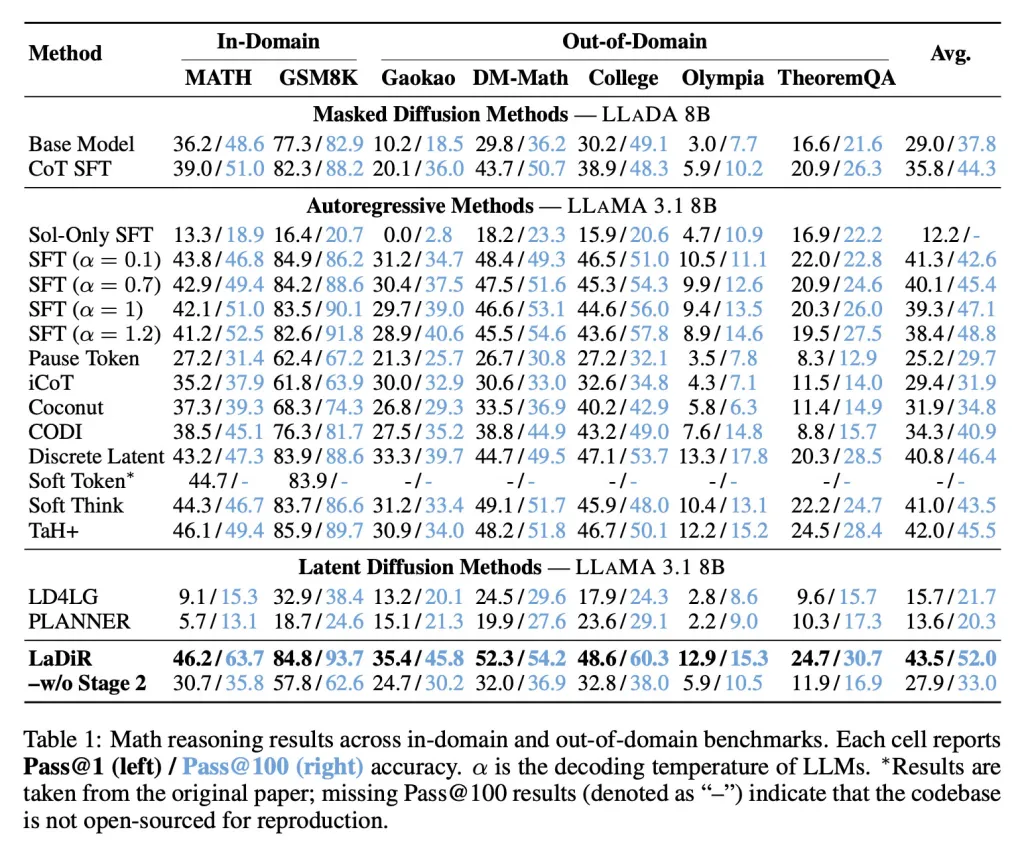
En métricas matemáticas, LaDiR logró una mayor precisión que los enfoques existentes y mostró un rendimiento más fuerte incluso en tareas más difíciles y fuera de distribución.
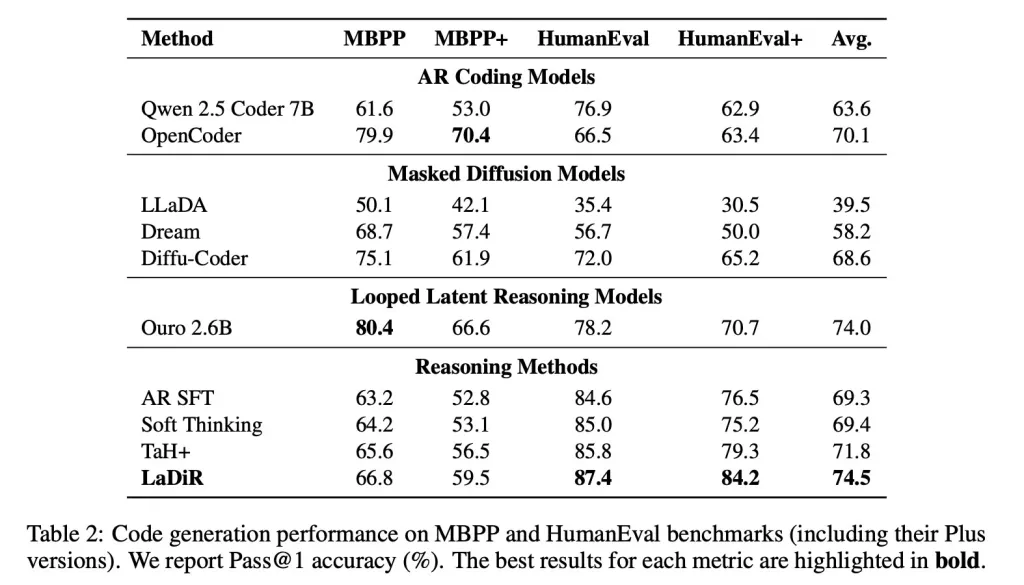
En métricas de generación de código, como HumanEval, LaDiR produjo salidas más confiables y superó claramente los ajustes estándar, especialmente en problemas más difíciles.
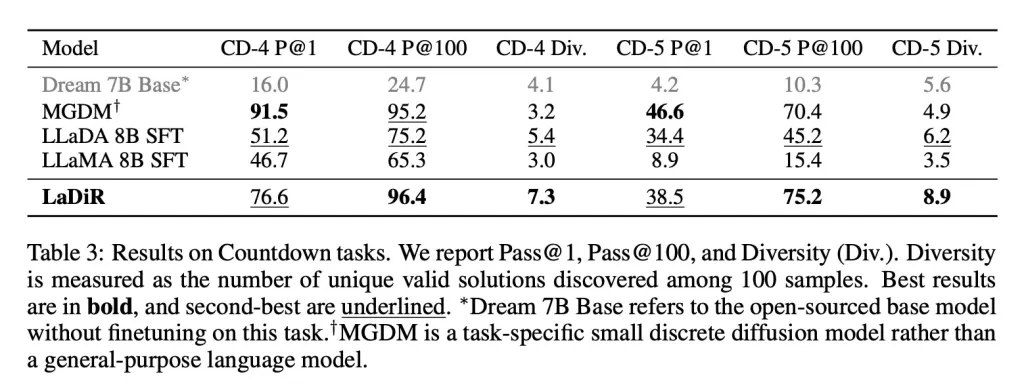
Y en tareas de planificación de estilo rompecabezas, como el juego Countdown, LaDiR exploró un rango más amplio de respuestas válidas que cualquier modelo base y encontró soluciones correctas de manera más confiable que todos los modelos de propósito general. Sin embargo, se quedó atrás de un modelo específico y enfocado en la tarea en términos de precisión en un solo intento.
Aunque algunos aspectos del artículo de LaDiR pueden ser bastante técnicos, vale la pena leerlo si estás interesado en el funcionamiento interno de los grandes modelos de lenguaje y en enfoques innovadores para mejorar el rendimiento en la generación de texto.
Sigue este enlace para leer el artículo completo.
























![La aplicación CardPointers ahora puede integrarse con ChatGPT y más [50% de descuento]](/resimler/cardpointers-uygulamasi-artik-chatgpt-ve-daha-fazlasi-ile-entegre-olabiliyor-yuzde-50-indirim.webp)














Comentarios
(10 Comentarios)