
Apple araştırmacılarından oluşan bir ekip, yüksek çözünürlüklü 3D sahne render'ını çok daha verimli bir şekilde gerçekleştiren yeni bir çerçeve geliştirdi. İşte yeni çalışmanın detayları.
Biraz bağlam
"Less Gaussians, Texture More: 4K Feed-Forward Textured Splatting" başlıklı yeni bir çalışmada, Apple ve Hong Kong Üniversitesi'nden bir grup araştırmacı, LGTM adı verilen yeni bir çerçeve öneriyor.
Çalışmada, araştırmacılar çözünürlük arttıkça mevcut feed-forward 3D Gaussian Splatting yöntemlerinin hızla çalıştırmanın çok pahalı hale geldiğini ve bu durumun yüksek çözünürlüklü sahneleri giderek daha da uygulanamaz hale getirdiğini açıklıyorlar.
Feed-forward 3D Gaussian Splatting, kısaca, bir yapay zeka modelinin bir veya birkaç görüntüyü hızlı bir şekilde yeni açılardan görüntülenebilen bir 3D sahneye dönüştürme yöntemidir.
Aslında, Apple tarafından geliştirilen SPLAT adında açık kaynaklı bir modeli yakın zamanda ele aldık. Bu model, tek bir 2D görüntüden 3D görünümler oluşturan feed-forward 3D Gaussian Splatting'i kullanıyor ve etkileyici sonuçlar veriyor:
Apple'dan yeni bir makale – Bir Saniyeden Daha Kısa Sürede Keskin Monoküler Görüntü Sentezi
— Tim Davison ᯅ (@timd_ca) 16 Aralık 2025
Mescheder ve arkadaşları @ Apple, çok etkileyici bir makale yayınladı (tebrikler! 🎉🥳). Bir görüntü veriyorsunuz ve gerçekten harika görünen bir 3D Gaussian temsili üretiyor. Derinlik pro kullanıyor. Gerçekten iyi.… pic.twitter.com/XSZCZA8iio
Feed-forward 3D Gaussian Splatting, her sahneyi bireysel olarak, adım adım oluşturan sahne başına optimizasyon yaklaşımlarından farklıdır. Genellikle daha uzun işlem süreleri almasına rağmen, daha stabil sonuçlar üretebilirler.
Yani, eski yaklaşımlar belirli bir sahneyi uyarlamak için daha fazla zaman harcarken, feed-forward yöntemleri çok daha hızlıdır; ancak mevcut versiyonlar daha yüksek çözünürlüklere ölçeklenmesi zor hale gelir.
LGTM
Bu sorunu ele almak için araştırmacılar, "geometrik karmaşıklığı render çözünürlüğünden ayıran" LGTM çerçevesini öneriyorlar.
Diğer bir deyişle, bir sahnenin yapısını görsel ayrıntısından ayırır, böylece sistem geometrinin basit kalmasını sağlarken yüksek çözünürlüklü ayrıntılar eklemek için dokuları kullanabilir.
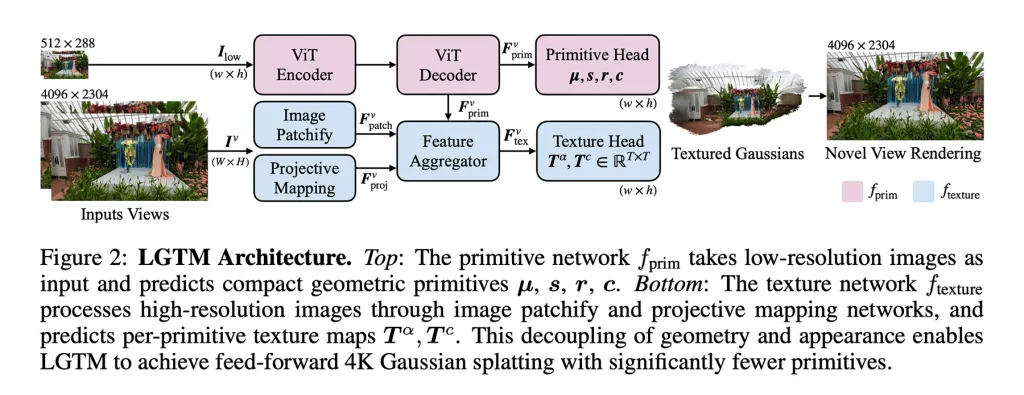
Önemli bir nokta, LGTM'nin bağımsız bir model olmamasıdır. Bunun yerine, mevcut feed-forward yöntemlerinin üzerine inşa ederek, detayları temsil etme biçimlerini, geometrilerinin üzerine doku tahminleri katmanlayarak geliştirmektedir.
Bunu yapma şekilleri iki aşamalıdır:
- Modelin düşük çözünürlüklü görüntülerden sahnenin yapısını öğrenmesini sağladılar, ardından çıktıyı yüksek çözünürlüklü gerçeklerle kontrol ettiler. Bu, modelin 2K veya 4K çözünürlükte render edildiğinde bile doğru görünen geometriler üretmeyi öğrenmesini sağladı ve boşluklar veya artefaktlardan kaçındı.
- Görünüm odaklı ikinci bir ağ tanıttılar. Bu, yüksek çözünürlüklü görüntüleri alır ve her geometrik eleman için detaylı dokuları öğrenir, böylece ilk modelden daha basit geometrinin üzerine ince görsel ayrıntılar katmanlamış olur.
Sonuç, mevcut sistemleri, daha önceki feed-forward yöntemlerin yüksek çözünürlüklerde uygulanmaz hale gelmesine neden olan hesaplama ihtiyaçlarındaki kare artış olmadan detaylı 4K sahneler üretebilecek bir çerçeve sunmaktadır.
Apple Vision Pro Gibi Ürünler İçin Ne Anlama Gelebilir?
Şu anda, Apple Vision Pro toplamda yaklaşık 23 milyon piksel içeren iki ekrana sahip, bu da her bir gözün bir 4K TV'den daha fazla piksel aldığı anlamına geliyor.
Çalışmanın gösterdiği gibi, feed-forward 3D Gaussian Splatting bu çözünürlüklerde zorlanıyor. Ekranlar bunu kaldırabiliyor, ancak sahneyi hızlı ve doğru bir şekilde oluşturmak hesaplama darboğazı haline geliyor.
LGTM, Apple Vision Pro'da bu durumu ele almaya yardımcı olabilir, bu da feed-forward 3D Gaussian Splatting'in gerekli olduğu durumlarda daha akıcı bir performans ve keskin görseller sunabilir.
Pratikte, bu, detaylı, sürükleyici ortamların veya daha gerçekçi geçiş deneyimlerinin tadını çıkarma fırsatlarını artırabilirken, işlem talebini de kontrol altında tutabilir.
LGTM'yi aksiyon halinde görmek için proje sayfasını ziyaret edin. Bu sayfa, LGTM ile ve onsuz NoPoSplat, DepthSplat ve Flash3D gibi yöntemleri tek görünüm ve iki görünüm girdileri arasında sergilemektedir.

Örnek videoları ve görüntüleri gözden geçirirken, LGTM'nin sonuçların çok daha zengin detaylarla (özellikle dokular ve metinler açısından) ve yerel gerçeklik görüntülerine (örnek görüntülerde GT olarak etiketlenmiştir) daha yakın sonuçlar üretmeye nasıl yardımcı olduğunu görmek oldukça kolay.
Örnek videoları ve görüntüleri gözden geçirirken, LGTM'nin sonuçların çok daha zengin detaylarla (özellikle dokular ve metinler açısından) ve yerel gerçeklik görüntülerine (örnek görüntülerde GT olarak etiketlenmiştir) daha yakın sonuçlar üretmeye nasıl yardımcı olduğunu görmek oldukça kolay.
Amazon'da Göz Atmaya Değer
- David Pogue – ’Apple: İlk 50 Yıl’
- MacBook Neo
- Logitech MX Master 4
- AirPods Pro 3
- AirTag (2. Nesil) – 4 Paket
- Apple Watch Series 11
- Kablosuz CarPlay adaptörü








































Yorumlar
(6 Yorum)