
Uma equipe de pesquisadores da Apple desenvolveu uma nova estrutura que realiza renderização de cenas 3D de alta resolução de forma muito mais eficiente. Aqui estão os detalhes do novo trabalho.
Um pouco de contexto
No novo trabalho intitulado "Menos Gaussiano, Mais Textura: Splatting Texturizado Feed-Forward 4K", um grupo de pesquisadores da Apple e da Universidade de Hong Kong propõe uma nova estrutura chamada LGTM.
No estudo, os pesquisadores explicam que, à medida que a resolução aumenta, os métodos existentes de Splatting Gaussiano 3D feed-forward se tornam rapidamente muito caros para serem executados, tornando cenas de alta resolução cada vez mais inviáveis.
Splatting Gaussiano 3D feed-forward, em resumo, é um método pelo qual um modelo de inteligência artificial converte uma ou mais imagens em uma cena 3D que pode ser visualizada rapidamente de novos ângulos.
Na verdade, recentemente abordamos um modelo de código aberto chamado SPLAT desenvolvido pela Apple. Este modelo utiliza Splatting Gaussiano 3D feed-forward para criar visualizações 3D a partir de uma única imagem 2D e produz resultados impressionantes:
Um novo artigo da Apple – Síntese de Imagem Monocular Nítida em Menos de Um Segundo
— Tim Davison ᯅ (@timd_ca) 16 de dezembro de 2025
Mescheder e colegas @ Apple publicaram um artigo muito impressionante (parabéns! 🎉🥳). Você fornece uma imagem e ele produz uma representação 3D Gaussiana que realmente parece incrível. Utiliza pro de profundidade. Realmente bom.… pic.twitter.com/XSZCZA8iio
Splatting Gaussiano 3D feed-forward é diferente das abordagens de otimização por cena que criam cada cena individualmente, passo a passo. Embora geralmente levem mais tempo de processamento, podem produzir resultados mais estáveis.
Ou seja, enquanto as abordagens antigas gastam mais tempo adaptando uma cena específica, os métodos feed-forward são muito mais rápidos; no entanto, as versões atuais tornam-se difíceis de escalar para resoluções mais altas.
LGTM
Para abordar esse problema, os pesquisadores propõem a estrutura LGTM, que "separa a complexidade geométrica da resolução de renderização".
Em outras palavras, ela separa a estrutura de uma cena dos detalhes visuais, permitindo que o sistema mantenha a geometria simples enquanto utiliza texturas para adicionar detalhes de alta resolução.
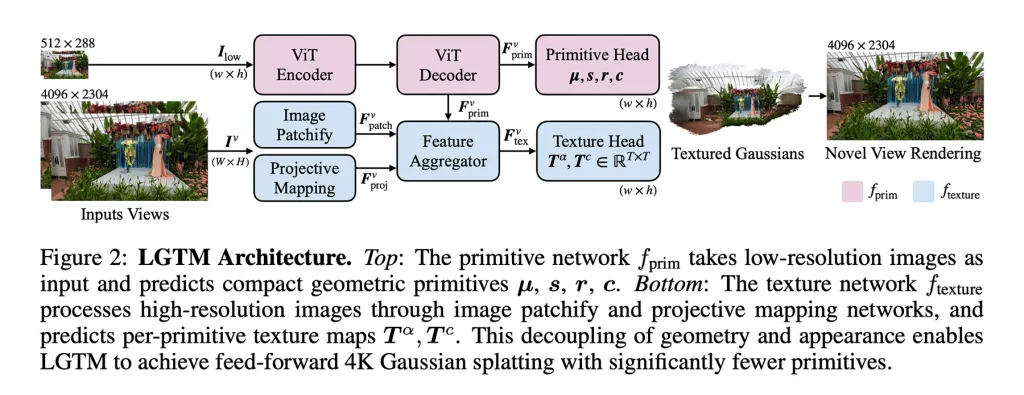
Um ponto importante é que o LGTM não é um modelo independente. Em vez disso, ele é construído sobre os métodos feed-forward existentes, aprimorando a forma como os detalhes são representados, sobrepondo previsões de textura sobre suas geometrias.
A maneira como fazem isso é em duas etapas:
- Eles permitiram que o modelo aprendesse a estrutura da cena a partir de imagens de baixa resolução e, em seguida, verificaram a saída com realidades de alta resolução. Isso permitiu que o modelo aprendesse a produzir geometrias que parecem corretas mesmo quando renderizadas em 2K ou 4K, evitando lacunas ou artefatos.
- Eles introduziram uma segunda rede focada em visualização. Esta recebe imagens de alta resolução e aprende texturas detalhadas para cada elemento geométrico, sobrepondo assim detalhes visuais finos sobre uma geometria mais simples do modelo inicial.
O resultado é uma estrutura que pode produzir cenas 4K detalhadas sem o aumento quadrático nas necessidades de computação que tornaram inviáveis os métodos feed-forward anteriores em altas resoluções.
O que isso pode significar para produtos como o Apple Vision Pro?
Atualmente, o Apple Vision Pro possui duas telas com um total de cerca de 23 milhões de pixels, o que significa que cada olho recebe mais pixels do que uma TV 4K.
Como o trabalho demonstrou, o Splatting Gaussiano 3D feed-forward enfrenta dificuldades nessas resoluções. As telas podem suportar isso, mas criar a cena de forma rápida e precisa se torna um gargalo computacional.
O LGTM pode ajudar a lidar com essa situação no Apple Vision Pro, o que pode proporcionar um desempenho mais fluido e visuais nítidos quando o Splatting Gaussiano 3D feed-forward é necessário.
Na prática, isso pode aumentar as oportunidades de desfrutar de ambientes detalhados e imersivos ou experiências de transição mais realistas, enquanto mantém a demanda de processamento sob controle.
Para ver o LGTM em ação, visite a página do projeto. Esta página exibe métodos como NoPoSplat, DepthSplat e Flash3D, com e sem LGTM, entre entradas de uma vista e duas vistas.

Enquanto revisa vídeos e imagens de exemplo, é bastante fácil ver como o LGTM ajuda a produzir resultados com detalhes muito mais ricos (especialmente em termos de texturas e textos) e resultados mais próximos das imagens de realidade local (etiquetadas como GT nas imagens de exemplo).
Enquanto revisa vídeos e imagens de exemplo, é bastante fácil ver como o LGTM ajuda a produzir resultados com detalhes muito mais ricos (especialmente em termos de texturas e textos) e resultados mais próximos das imagens de realidade local (etiquetadas como GT nas imagens de exemplo).
Vale a pena conferir na Amazon
- David Pogue – 'Apple: Os Primeiros 50 Anos'
- MacBook Neo
- Logitech MX Master 4
- AirPods Pro 3
- AirTag (2ª Geração) – Pacote com 4
- Apple Watch Series 11
- Adaptador CarPlay sem fio










































Comentários
(6 Comentários)