
Une équipe de chercheurs d'Apple a développé un nouveau cadre qui réalise le rendu de scènes 3D haute résolution de manière beaucoup plus efficace. Voici les détails de ce nouveau travail.
Un peu de contexte
Dans un nouvel article intitulé "Less Gaussians, Texture More: 4K Feed-Forward Textured Splatting", un groupe de chercheurs d'Apple et de l'Université de Hong Kong propose un nouveau cadre appelé LGTM.
Dans cette étude, les chercheurs expliquent que les méthodes de Splatting Gaussien 3D feed-forward existantes deviennent rapidement coûteuses à exécuter à mesure que la résolution augmente, rendant ainsi les scènes haute résolution de plus en plus impraticables.
Le Splatting Gaussien 3D feed-forward est, en résumé, une méthode par laquelle un modèle d'intelligence artificielle transforme une ou plusieurs images en une scène 3D pouvant être visualisée sous de nouveaux angles rapidement.
En fait, nous avons récemment examiné un modèle open source développé par Apple appelé SPLAT. Ce modèle utilise le Splatting Gaussien 3D feed-forward pour créer des vues 3D à partir d'une seule image 2D et produit des résultats impressionnants :
Un nouvel article d'Apple – Synthèse d'images monoscopiques nettes en moins d'une seconde
— Tim Davison ᯅ (@timd_ca) 16 décembre 2025
Mescheder et ses collègues @ Apple ont publié un article très impressionnant (félicitations ! 🎉🥳). Vous fournissez une image et il produit une représentation 3D Gaussienne qui a vraiment l'air géniale. Il utilise le pro de profondeur. Vraiment bien.… pic.twitter.com/XSZCZA8iio
Le Splatting Gaussien 3D feed-forward diffère des approches d'optimisation par scène qui construisent chaque scène individuellement, étape par étape. Bien qu'elles prennent généralement plus de temps de traitement, elles peuvent produire des résultats plus stables.
Ainsi, tandis que les anciennes approches passent plus de temps à adapter une scène particulière, les méthodes feed-forward sont beaucoup plus rapides ; cependant, les versions existantes deviennent difficiles à mettre à l'échelle vers des résolutions plus élevées.
LGTM
Pour aborder ce problème, les chercheurs proposent le cadre LGTM, qui "dissocie la complexité géométrique de la résolution de rendu".
Autrement dit, il dissocie la structure d'une scène des détails visuels, permettant ainsi au système de garder la géométrie simple tout en utilisant des textures pour ajouter des détails haute résolution.
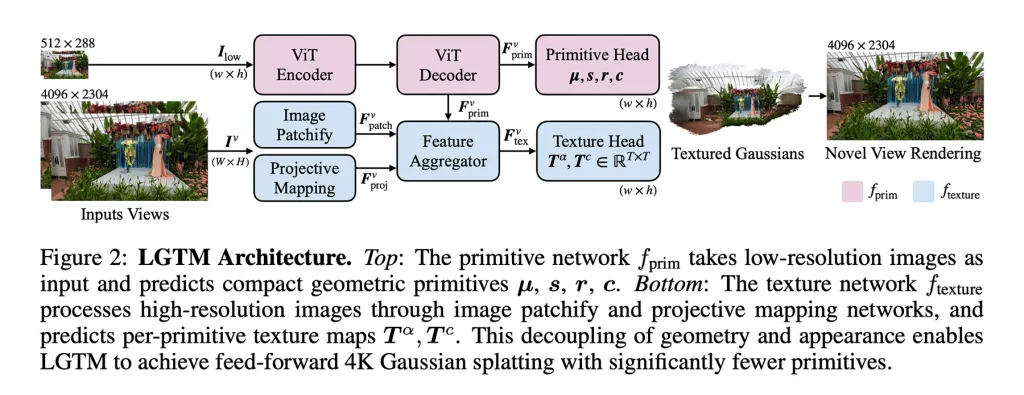
Un point important est que LGTM n'est pas un modèle indépendant. Au lieu de cela, il est construit sur les méthodes feed-forward existantes, améliorant la façon dont les détails sont représentés en superposant des prédictions de texture sur leurs géométries.
Leur façon de procéder est en deux étapes :
- Ils ont permis au modèle d'apprendre la structure de la scène à partir d'images basse résolution, puis ont vérifié la sortie avec des vérités haute résolution. Cela a permis au modèle d'apprendre à produire des géométries qui semblent correctes même lorsqu'elles sont rendues à 2K ou 4K, évitant ainsi les espaces vides ou les artefacts.
- Ils ont introduit un deuxième réseau axé sur la vue. Celui-ci prend des images haute résolution et apprend des textures détaillées pour chaque élément géométrique, superposant ainsi des détails visuels fins sur une géométrie plus simple que le modèle initial.
Le résultat est un cadre qui permet de produire des scènes 4K détaillées sans l'augmentation quadratique des besoins de calcul qui rendait auparavant les anciennes méthodes feed-forward impraticables à des résolutions élevées.
Que cela pourrait-il signifier pour des produits comme Apple Vision Pro ?
Actuellement, l'Apple Vision Pro dispose de deux écrans contenant environ 23 millions de pixels au total, ce qui signifie que chaque œil reçoit plus de pixels qu'une télévision 4K.
Comme l'indique l'étude, le Splatting Gaussien 3D feed-forward a des difficultés à ces résolutions. Les écrans peuvent le supporter, mais créer la scène rapidement et avec précision devient un goulet d'étranglement de calcul.
LGTM pourrait aider à résoudre cette situation sur l'Apple Vision Pro, permettant ainsi un meilleur rendement et des visuels nets lorsque le Splatting Gaussien 3D feed-forward est nécessaire.
En pratique, cela pourrait augmenter les opportunités de profiter d'environnements détaillés et immersifs ou d'expériences de transition plus réalistes, tout en gardant la demande de traitement sous contrôle.
Pour voir LGTM en action, visitez la page du projet. Cette page présente des méthodes comme NoPoSplat, DepthSplat et Flash3D avec et sans LGTM entre des entrées à vue unique et à double vue.

En examinant des vidéos et des images d'exemple, il est très facile de voir comment LGTM aide à produire des résultats avec des détails beaucoup plus riches (en particulier en termes de textures et de textes) et des résultats plus proches des images de réalité locale (étiquetées GT dans les images d'exemple).
En examinant des vidéos et des images d'exemple, il est très facile de voir comment LGTM aide à produire des résultats avec des détails beaucoup plus riches (en particulier en termes de textures et de textes) et des résultats plus proches des images de réalité locale (étiquetées GT dans les images d'exemple).
A voir sur Amazon
- David Pogue – 'Apple: Les 50 premières années'
- MacBook Neo
- Logitech MX Master 4
- AirPods Pro 3
- AirTag (2e génération) – paquet de 4
- Apple Watch Series 11
- Adaptateur CarPlay sans fil










































![iPhone 17e : Apple a enfin réussi à créer un iPhone abordable [Vidéo]](/resimler/iphone-17e-apple-nihayet-uygun-fiyatli-iphoneu-dogru-yapti-video.jpg)

Commentaires
(6 Commentaires)