
Un team di ricercatori di Apple ha sviluppato un nuovo framework che realizza il rendering di scene 3D ad alta risoluzione in modo molto più efficiente. Ecco i dettagli del nuovo lavoro.
Un po' di contesto
In un nuovo studio intitolato "Less Gaussians, Texture More: 4K Feed-Forward Textured Splatting", un gruppo di ricercatori di Apple e dell'Università di Hong Kong propone un nuovo framework chiamato LGTM.
Nello studio, i ricercatori spiegano che, man mano che la risoluzione aumenta, i metodi esistenti di feed-forward 3D Gaussian Splatting diventano rapidamente molto costosi da eseguire e che questa situazione rende le scene ad alta risoluzione sempre più impraticabili.
Il feed-forward 3D Gaussian Splatting è, in breve, un metodo in cui un modello di intelligenza artificiale trasforma rapidamente una o più immagini in una scena 3D visualizzabile da nuove angolazioni.
In effetti, abbiamo recentemente trattato un modello open source chiamato SPLAT sviluppato da Apple. Questo modello utilizza il feed-forward 3D Gaussian Splatting per generare viste 3D da un'unica immagine 2D e produce risultati impressionanti:
Un nuovo articolo da Apple – Sintesi di Immagini Monoculari Nitide in Meno di Un Secondo
— Tim Davison ᯅ (@timd_ca) 16 dicembre 2025
Mescheder e colleghi @ Apple hanno pubblicato un articolo molto impressionante (complimenti! 🎉🥳). Dai un'immagine e produce una rappresentazione 3D Gaussian che appare davvero fantastica. Utilizza il deep pro. Davvero buono.… pic.twitter.com/XSZCZA8iio
Il feed-forward 3D Gaussian Splatting è diverso dagli approcci di ottimizzazione per scena che costruiscono ogni scena individualmente, passo dopo passo. Sebbene richiedano generalmente tempi di elaborazione più lunghi, possono produrre risultati più stabili.
Quindi, mentre i vecchi approcci spendono più tempo per adattare una scena specifica, i metodi feed-forward sono molto più veloci; tuttavia, le versioni attuali diventano difficili da scalare a risoluzioni più elevate.
LGTM
Per affrontare questo problema, i ricercatori propongono il framework LGTM, che "separa la complessità geometrica dalla risoluzione di rendering".
In altre parole, separa la struttura di una scena dai dettagli visivi, consentendo al sistema di mantenere la geometria semplice mentre utilizza le texture per aggiungere dettagli ad alta risoluzione.
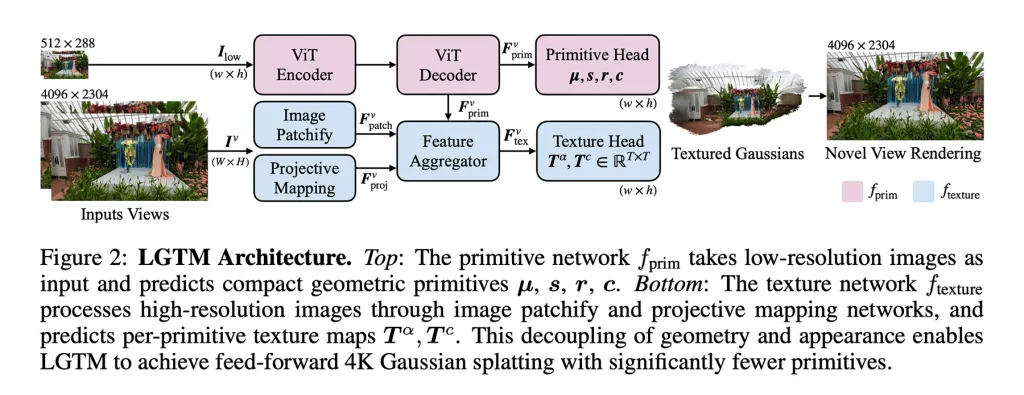
Un punto importante è che LGTM non è un modello indipendente. Invece, costruisce sopra i metodi feed-forward esistenti, migliorando i modi in cui rappresentano i dettagli sovrapponendo previsioni di texture sulle loro geometrie.
Il loro modo di farlo è in due fasi:
- Hanno fatto in modo che il modello imparasse la struttura della scena da immagini a bassa risoluzione, quindi hanno controllato l'output con realtà ad alta risoluzione. Questo ha permesso al modello di apprendere a produrre geometrie che sembrano corrette anche quando renderizzate a risoluzioni di 2K o 4K, evitando spazi vuoti o artefatti.
- Hanno introdotto una seconda rete focalizzata sulla vista. Questa prende immagini ad alta risoluzione e apprende texture dettagliate per ogni elemento geometrico, sovrapponendo così dettagli visivi fini su geometrie più semplici rispetto al primo modello.
Il risultato è un framework che può produrre scene 4K dettagliate senza l'aumento quadratico delle esigenze computazionali che rendeva impraticabili i metodi feed-forward precedenti a risoluzioni elevate.
Cosa Potrebbe Significare Per Prodotti Come Apple Vision Pro?
Attualmente, Apple Vision Pro ha due schermi che contengono un totale di circa 23 milioni di pixel, il che significa che ogni occhio riceve più pixel di una TV 4K.
Come dimostra lo studio, il feed-forward 3D Gaussian Splatting ha difficoltà a queste risoluzioni. Gli schermi possono gestirlo, ma costruire la scena in modo rapido e preciso diventa un collo di bottiglia computazionale.
LGTM potrebbe aiutare a risolvere questa situazione su Apple Vision Pro, il che potrebbe offrire prestazioni più fluide e immagini nitide nei casi in cui è necessario il feed-forward 3D Gaussian Splatting.
In pratica, questo potrebbe aumentare le opportunità di godere di ambienti dettagliati e coinvolgenti o di esperienze di transizione più realistiche, mantenendo sotto controllo la domanda di elaborazione.
Visita la pagina del progetto per vedere LGTM in azione. Questa pagina mostra metodi come NoPoSplat, DepthSplat e Flash3D, sia con che senza LGTM, tra input a vista singola e doppia.

Esaminando i video e le immagini di esempio, è abbastanza facile vedere come LGTM aiuti a produrre risultati con dettagli molto più ricchi (soprattutto in termini di texture e testi) e risultati più vicini alle immagini di realtà locale (etichettate come GT nelle immagini di esempio).
Esaminando i video e le immagini di esempio, è abbastanza facile vedere come LGTM aiuti a produrre risultati con dettagli molto più ricchi (soprattutto in termini di texture e testi) e risultati più vicini alle immagini di realtà locale (etichettate come GT nelle immagini di esempio).
Da Esplorare su Amazon
- David Pogue – 'Apple: I Primi 50 Anni'
- MacBook Neo
- Logitech MX Master 4
- AirPods Pro 3
- AirTag (2° Generazione) – Pacco da 4
- Apple Watch Series 11
- Adattatore CarPlay Wireless











![L'applicazione CardPointers ora può integrarsi con ChatGPT e altro ancora [50% di sconto]](/resimler/cardpointers-uygulamasi-artik-chatgpt-ve-daha-fazlasi-ile-entegre-olabiliyor-yuzde-50-indirim.webp)






























Commenti
(6 Commenti)