
A team of researchers from Apple has developed a new framework that performs high-resolution 3D scene rendering much more efficiently. Here are the details of the new study.
Some Context
In a new study titled "Less Gaussians, Texture More: 4K Feed-Forward Textured Splatting," a group of researchers from Apple and the University of Hong Kong proposes a new framework called LGTM.
In the study, the researchers explain that as resolution increases, the existing feed-forward 3D Gaussian Splatting methods become very expensive to run quickly, making high-resolution scenes increasingly impractical.
Feed-forward 3D Gaussian Splatting, in short, is a method for quickly converting one or several images into a 3D scene that can be viewed from new angles using an artificial intelligence model.
In fact, we recently covered an open-source model developed by Apple called SPLAT. This model uses feed-forward 3D Gaussian Splatting to create 3D views from a single 2D image and delivers impressive results:
A new paper from Apple – Sharp Monocular Image Synthesis in Less Than a Second
— Tim Davison ᯅ (@timd_ca) December 16, 2025
Mescheder and colleagues @ Apple published a very impressive paper (congratulations! 🎉🥳). You provide an image, and it produces a 3D Gaussian representation that looks really great. It uses depth pro. Really good.… pic.twitter.com/XSZCZA8iio
Feed-forward 3D Gaussian Splatting differs from optimization approaches that create each scene individually, step by step. Although they generally take longer processing times, they can produce more stable results.
So, while older approaches spend more time adapting a specific scene, feed-forward methods are much faster; however, the current versions become difficult to scale to higher resolutions.
LGTM
To address this issue, the researchers propose the LGTM framework, which "separates geometric complexity from rendering resolution."
In other words, it separates the structure of a scene from its visual detail, allowing the system to keep the geometry simple while using textures to add high-resolution details.
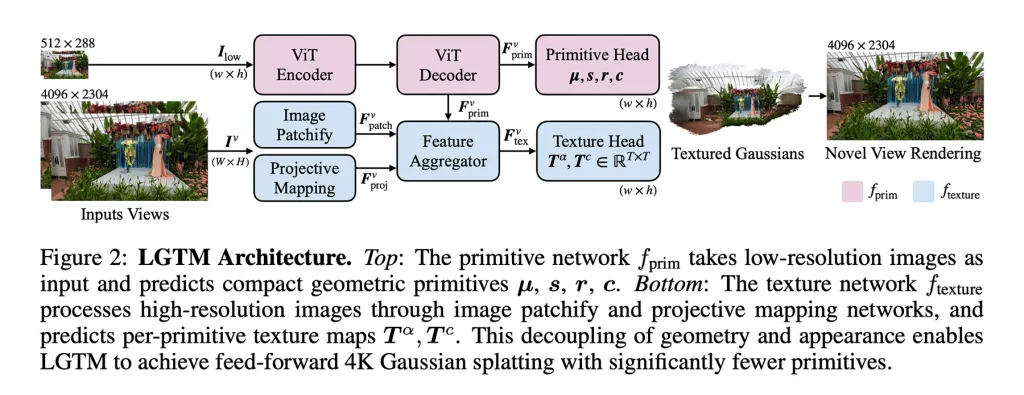
An important point is that LGTM is not an independent model. Instead, it builds on existing feed-forward methods, enhancing the way details are represented by layering texture predictions over their geometries.
Their approach is twofold:
- They enabled the model to learn the structure of the scene from low-resolution images and then checked the output against high-resolution realities. This allowed the model to learn to produce geometries that look correct even when rendered at 2K or 4K resolution, avoiding gaps or artifacts.
- They introduced a second network focused on views. This takes high-resolution images and learns detailed textures for each geometric element, layering fine visual details over simpler geometries from the first model.
The result is a framework that can produce detailed 4K scenes without the square increase in computational demands that made previous feed-forward methods impractical at high resolutions.
What Could This Mean for Products Like Apple Vision Pro?
Currently, the Apple Vision Pro has two screens with a total of about 23 million pixels, meaning each eye receives more pixels than a 4K TV.
As the study shows, feed-forward 3D Gaussian Splatting struggles at these resolutions. The screens can handle it, but rendering the scene quickly and accurately becomes a computational bottleneck.
LGTM could help address this situation in the Apple Vision Pro, potentially providing smoother performance and sharper visuals when feed-forward 3D Gaussian Splatting is necessary.
In practice, this could increase opportunities to enjoy detailed, immersive environments or more realistic transition experiences while keeping processing demands under control.
To see LGTM in action, visit the project page. This page showcases methods like NoPoSplat, DepthSplat, and Flash3D with and without LGTM between single-view and dual-view inputs.

While reviewing example videos and images, it is quite easy to see how LGTM helps produce results with much richer details (especially in terms of textures and texts) and results closer to local reality images (labeled as GT in the example images).
While reviewing example videos and images, it is quite easy to see how LGTM helps produce results with much richer details (especially in terms of textures and texts) and results closer to local reality images (labeled as GT in the example images).
Worth Browsing on Amazon
- David Pogue – 'Apple: The First 50 Years'
- MacBook Neo
- Logitech MX Master 4
- AirPods Pro 3
- AirTag (2nd Generation) – 4 Pack
- Apple Watch Series 11
- Wireless CarPlay Adapter





































Comments
(6 Comments)