
Un equipo de investigadores de Apple ha desarrollado un nuevo marco que realiza renderizados de escenas 3D de alta resolución de manera mucho más eficiente. Aquí están los detalles del nuevo trabajo.
Un poco de contexto
En un nuevo trabajo titulado "Menos Gaussianos, Más Textura: Splatting Texturizado Feed-Forward 4K", un grupo de investigadores de Apple y de la Universidad de Hong Kong propone un nuevo marco llamado LGTM.
En el estudio, los investigadores explican que, a medida que aumenta la resolución, los métodos existentes de Splatting Gaussiano 3D Feed-Forward se vuelven muy costosos de ejecutar rápidamente, lo que hace que las escenas de alta resolución sean cada vez más inviables.
El Splatting Gaussiano 3D Feed-Forward es, en resumen, un método mediante el cual un modelo de inteligencia artificial convierte una o varias imágenes en una escena 3D que se puede visualizar rápidamente desde nuevos ángulos.
De hecho, recientemente abordamos un modelo de código abierto llamado SPLAT desarrollado por Apple. Este modelo utiliza Splatting Gaussiano 3D Feed-Forward para crear vistas 3D a partir de una sola imagen 2D y produce resultados impresionantes:
Un nuevo artículo de Apple – Síntesis de Imágenes Monoculares Nítidas en Menos de un Segundo
— Tim Davison ᯅ (@timd_ca) 16 de diciembre de 2025
Mescheder y sus colegas en @Apple publicaron un artículo muy impresionante (¡felicitaciones! 🎉🥳). Das una imagen y produce una representación 3D Gaussiana que se ve realmente genial. Usa Deep Pro. Realmente bueno.… pic.twitter.com/XSZCZA8iio
El Splatting Gaussiano 3D Feed-Forward se diferencia de los enfoques de optimización por escena que crean cada escena individualmente, paso a paso. Aunque generalmente pueden tomar más tiempo de procesamiento, pueden producir resultados más estables.
Es decir, mientras que los enfoques antiguos gastan más tiempo adaptando una escena específica, los métodos feed-forward son mucho más rápidos; sin embargo, las versiones actuales se vuelven difíciles de escalar a resoluciones más altas.
LGTM
Para abordar este problema, los investigadores proponen el marco LGTM, que "separa la complejidad geométrica de la resolución de renderizado".
En otras palabras, separa la estructura de una escena de su detalle visual, permitiendo que el sistema mantenga la geometría simple mientras utiliza texturas para agregar detalles de alta resolución.
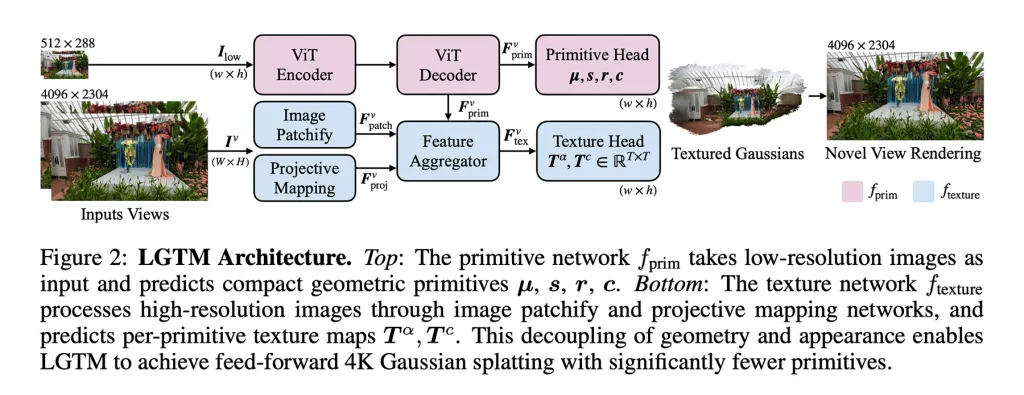
Un punto importante es que LGTM no es un modelo independiente. En cambio, se construye sobre los métodos feed-forward existentes, mejorando la forma en que representan los detalles al superponer predicciones de textura sobre sus geometrías.
Su forma de hacerlo es de dos etapas:
- Hicieron que el modelo aprendiera la estructura de la escena a partir de imágenes de baja resolución, y luego verificaron la salida con realidades de alta resolución. Esto permitió que el modelo aprendiera a producir geometrías que se ven correctas incluso cuando se renderizan a 2K o 4K, evitando huecos o artefactos.
- Introdujeron una segunda red enfocada en la vista. Esta toma imágenes de alta resolución y aprende texturas detalladas para cada elemento geométrico, de modo que superpone detalles visuales finos sobre geometrías más simples que el modelo inicial.
El resultado es un marco que puede producir escenas 4K detalladas sin el aumento cuadrático en las necesidades computacionales que hacía que los métodos feed-forward anteriores fueran inviables a altas resoluciones.
¿Qué podría significar para productos como Apple Vision Pro?
Actualmente, Apple Vision Pro tiene dos pantallas que contienen un total de aproximadamente 23 millones de píxeles, lo que significa que cada ojo recibe más píxeles que un televisor 4K.
Como muestra el estudio, el Splatting Gaussiano 3D Feed-Forward tiene dificultades a estas resoluciones. Las pantallas pueden manejarlo, pero crear la escena de manera rápida y precisa se convierte en un cuello de botella computacional.
LGTM podría ayudar a abordar esta situación en Apple Vision Pro, lo que podría ofrecer un rendimiento más fluido y gráficos nítidos en situaciones donde se requiere Splatting Gaussiano 3D Feed-Forward.
En la práctica, esto podría aumentar las oportunidades de disfrutar de entornos detallados e inmersivos o experiencias de transición más realistas, mientras mantiene bajo control la demanda de procesamiento.
Visita la página del proyecto para ver LGTM en acción. Esta página presenta métodos como NoPoSplat, DepthSplat y Flash3D, con y sin LGTM, entre entradas de una y dos vistas.

Al revisar los videos y las imágenes de ejemplo, es bastante fácil ver cómo LGTM ayuda a producir resultados mucho más ricos en detalles (especialmente en términos de texturas y textos) y más cercanos a las imágenes de realidad local (etiquetadas como GT en las imágenes de ejemplo).
Al revisar los videos y las imágenes de ejemplo, es bastante fácil ver cómo LGTM ayuda a producir resultados mucho más ricos en detalles (especialmente en términos de texturas y textos) y más cercanos a las imágenes de realidad local (etiquetadas como GT en las imágenes de ejemplo).
Vale la pena explorar en Amazon
- David Pogue – 'Apple: Los Primeros 50 Años'
- MacBook Neo
- Logitech MX Master 4
- AirPods Pro 3
- AirTag (2ª Generación) – Paquete de 4
- Apple Watch Series 11
- Adaptador CarPlay Inalámbrico











































Comentarios
(6 Comentarios)