
Ein Team von Apple-Forschern hat ein neues Framework entwickelt, das hochauflösende 3D-Szenen-Renderings viel effizienter durchführt. Hier sind die Details der neuen Arbeit.
Ein wenig Kontext
In einer neuen Arbeit mit dem Titel "Less Gaussians, Texture More: 4K Feed-Forward Textured Splatting" schlagen Forscher von Apple und der Universität Hongkong ein neues Framework namens LGTM vor.
In der Arbeit erklären die Forscher, dass die aktuellen Feed-Forward 3D Gaussian Splatting-Methoden schnell sehr kostspielig werden, je höher die Auflösung ist, und dass dies hochauflösende Szenen zunehmend unpraktisch macht.
Feed-Forward 3D Gaussian Splatting ist kurz gesagt eine Methode, bei der ein KI-Modell ein oder mehrere Bilder schnell in eine 3D-Szene umwandelt, die aus neuen Blickwinkeln betrachtet werden kann.
Tatsächlich haben wir kürzlich ein von Apple entwickeltes Open-Source-Modell namens SPLAT behandelt. Dieses Modell verwendet Feed-Forward 3D Gaussian Splatting, um 3D-Ansichten aus einem einzigen 2D-Bild zu erstellen und liefert beeindruckende Ergebnisse:
Ein neuer Artikel von Apple – Scharfe monokulare Bildsynthese in weniger als einer Sekunde
— Tim Davison ᯅ (@timd_ca) 16. Dezember 2025
Mescheder und Kollegen @ Apple haben einen sehr beeindruckenden Artikel veröffentlicht (Herzlichen Glückwunsch! 🎉🥳). Sie geben ein Bild ein und es produziert eine wirklich großartig aussehende 3D-Gaussian-Darstellung. Es verwendet Depth Pro. Wirklich gut.… pic.twitter.com/XSZCZA8iio
Feed-Forward 3D Gaussian Splatting unterscheidet sich von Optimierungsansätzen pro Szene, die jede Szene einzeln Schritt für Schritt erstellen. Obwohl sie in der Regel längere Verarbeitungszeiten benötigen, können sie stabilere Ergebnisse liefern.
Das bedeutet, dass ältere Ansätze mehr Zeit aufwenden, um eine bestimmte Szene anzupassen, während Feed-Forward-Methoden viel schneller sind; jedoch wird es für die aktuellen Versionen schwierig, auf höhere Auflösungen zu skalieren.
LGTM
Um dieses Problem anzugehen, schlagen die Forscher das LGTM-Framework vor, das "die geometrische Komplexität von der Renderauflösung trennt".
Mit anderen Worten, es trennt die Struktur einer Szene von den visuellen Details, sodass das System die Geometrie einfach halten kann, während es Texturen verwendet, um hochauflösende Details hinzuzufügen.
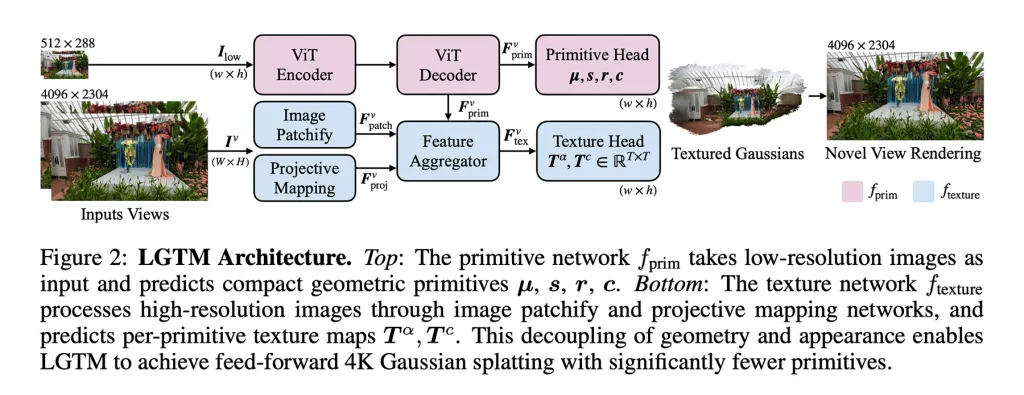
Ein wichtiger Punkt ist, dass LGTM kein eigenständiges Modell ist. Stattdessen baut es auf bestehenden Feed-Forward-Methoden auf und verbessert die Art und Weise, wie Details dargestellt werden, indem es Texturvorhersagen über deren Geometrien schichtet.
Ihr Ansatz besteht aus zwei Phasen:
- Sie ließen das Modell die Struktur der Szene aus niedrigauflösenden Bildern lernen und überprüften dann die Ausgaben mit hochauflösenden Realitäten. Dies ermöglichte es dem Modell, Geometrien zu erzeugen, die selbst bei einer Renderung in 2K oder 4K korrekt aussahen und Leerstellen oder Artefakte vermieden.
- Sie führten ein zweites, ansichtsfokussiertes Netzwerk ein. Dieses nimmt hochauflösende Bilder auf und lernt detaillierte Texturen für jedes geometrische Element, sodass es feine visuelle Details auf einfachere Geometrien des ersten Modells schichten kann.
Das Ergebnis ist ein Framework, das bestehende Systeme in die Lage versetzt, detaillierte 4K-Szenen zu produzieren, ohne die quadratische Zunahme der Rechenanforderungen, die frühere Feed-Forward-Methoden unpraktisch für hohe Auflösungen machte.
Was könnte das für Produkte wie Apple Vision Pro bedeuten?
Derzeit verfügt Apple Vision Pro über zwei Bildschirme mit insgesamt etwa 23 Millionen Pixeln, was bedeutet, dass jedes Auge mehr Pixel erhält als ein 4K-Fernseher.
Wie die Arbeit zeigt, hat Feed-Forward 3D Gaussian Splatting Schwierigkeiten bei diesen Auflösungen. Die Bildschirme können dies bewältigen, aber die Erstellung der Szene wird zum Rechenengpass.
LGTM könnte helfen, diese Situation im Apple Vision Pro zu bewältigen, was zu flüssigerer Leistung und schärferen Grafiken führen könnte, wenn Feed-Forward 3D Gaussian Splatting erforderlich ist.
In der Praxis könnte dies die Möglichkeiten erhöhen, detaillierte, immersive Umgebungen oder realistischere Übergangserlebnisse zu genießen, während die Verarbeitungsanforderungen unter Kontrolle gehalten werden.
Um LGTM in Aktion zu sehen, besuchen Sie die Projektseite. Diese Seite zeigt Methoden wie NoPoSplat, DepthSplat und Flash3D mit und ohne LGTM zwischen Einzel- und Doppelansichtseingaben.

Beim Durchsehen von Beispielvideos und Bildern ist es ziemlich einfach zu sehen, wie LGTM dabei hilft, Ergebnisse mit viel reichhaltigeren Details (insbesondere in Bezug auf Texturen und Texte) und näher an den lokalen Realitätsbildern (in den Beispielbildern als GT gekennzeichnet) zu produzieren.
Beim Durchsehen von Beispielvideos und Bildern ist es ziemlich einfach zu sehen, wie LGTM dabei hilft, Ergebnisse mit viel reichhaltigeren Details (insbesondere in Bezug auf Texturen und Texte) und näher an den lokalen Realitätsbildern (in den Beispielbildern als GT gekennzeichnet) zu produzieren.
Wertvolle Entdeckungen bei Amazon
- David Pogue – 'Apple: Die ersten 50 Jahre'
- MacBook Neo
- Logitech MX Master 4
- AirPods Pro 3
- AirTag (2. Generation) – 4er-Pack
- Apple Watch Series 11
- Drahtloser CarPlay-Adapter









































Kommentare
(6 Kommentare)